
【论文阅读】:Med-Former: A Transformer-based Architecture for Medical Image Classification

⭐论文信息
1.1 拟解决的科学问题
✨ 本论文旨在解决Transformer在医学图像分类任务中的应用问题,主要解决了Transformer在医学图像分类任务中特征提取不佳和不能很好地传播有效的信息的问题。
✨ 本文属于医学图像分类领域,我还将其归为多尺度融合领域,具体涉及到局部全局特征融合领域。
⭐论文背景
2.1 基本背景和前提技术
✨ 多尺度融合:多尺度融合是指将不同尺度的特征进行融合,以提高特征的表达能力,在图像特征提取中,多尺度融合常表明图像的不同分辨率的特征融合,例如在CNN中设计的多尺度卷积核,卷积核的大小不同,意味着卷积核能够提取不同尺度的特征:越小的卷积核提取的是细节特征,越大的卷积核提取的是全局特征,如何将这些各种尺度的特征融合起来,学术界称之为多尺度融合任务。
✨ Swin-Transformer:Swin-Transformer是一种图像领域的新的Transformer模型,该模型将图像分成了大量块,每一块都是一个小的图像块,称之为Patch,传统的视觉transformer模型会直接将每个Patch和其他Patch计算注意力分数,然而考虑到计算效率,Swin-Transfomer再将若干的Patch组成一个窗口,也称之为Window,然后再计算每个窗内Patch和其他Patch的注意力分数,之后再设计了一个Shift Window的机制,将Patch的位置信息传递给下一层,具体来说,就是将窗口进行滑动,使得原本不在同一个窗口内的Patch,滑窗后可能在同一个窗口内,这样就能够保证Patch之间的位置信息能够传递到下一层。这种设计共使用俩次注意力机制,一次是window Patch内注意力(W-MSA),一次是shift window Patch注意力(SW-MSA),这种设计使得Swin-Transformer在图像分类任务中取得了非常好的效果。
2.2 挖坑
✨ 医学图像分类面临疾病内在复杂性的挑战,比如病变区域小,对比度低,与其他区域相似。
However, medical image classification presents challenges due to the intrinsic complexities of diseases, such as very small infected regions (e.g., nodules in chest x-rays), poor contrast between background and infected regions, and diseased areas resembling other normal areas (e.g., diseased black dots on skin similar to mole marks).
好像就挖了这一个坑??
2.3 相关工作
✨ CNN: 尽管CNN在图像特征提取任务中取得了巨大成功,但是CNN在医学图像分类任务中存在一些问题,CNN内在缺陷是难以整合上下文信息,只关注局部区域,难以对全局特征进行整合。
Despite their remarkable performance, CNNs have inherent limitations. For instance, each convolutional kernel can only focus on a sub-region of the input image due to its inherent inductive biases, complicating the extraction of global contextual information crucial for medical image classification.
✨ Inception networks:为了解决CNN的困境,Inception网络提出了多尺度卷积核,以提取不同尺度的特征,但是Inception网络容易遇到梯度消失和信息丢失的问题。
To tackle this challenge, researchers introduced Inception networks [17], capable of extracting multi-scale information. However, these networks encounter issues such as vanishing gradients and information loss from earlier layers.
✨ Residual networks & DenseNets:为了解决梯度消失和信息丢失的问题,ResNet和DenseNet提出了残差连接和密集连接,但是这些网络仍然存在一些问题,它没办法将注意力关注到重要的区域。
Although these networks capture information from earlier layers, they may not enable the model to focus attentions on specific regions essential for medical image classification, as they lack attention mechanisms to emphasize important features.
✨ Transformer:基于Transformer的视觉模型,如ViT和Swin-Transformer,尽管它们可以有效利用上下文信息,但是它们难以有效整合局部特征与全局特征,还可能遇到信息丢失的问题。
Recently, Transformer-based approaches with self-attention mechanisms have been developed for image recognition, such as Vision Transformers (ViT) [3], capable of capturing better contextual information compared to CNNs [6,10]. These methods partition the input image into non-overlapping patches and utilize a window (a collection of patches) for self-attention computation. To further enhance contextual information extraction, researchers introduced Swin Transformers [12]. These networks employ sequentially connected two transformer blocks with different window strategies for computing self-attention. However, these networks do not fully capture information at local and global levels and suffer from information loss from earlier layers.
2.4 一句话总结技术
为了解决这些限制,我们引入了 Med-Former,这是一种基于transformer的方法,擅长增强在本地和全局级别提取重要信息的能力,同时缓解在网络的各个层中传播重要信息期间的信息丢失问题。
To address these limitations, we introduce Med-Former, a transformer-based approach adept at enhancing the capability of extracting essential information at both local and global levels while mitigating issues of information loss during the propagation of essential information throughout various layers of the network.
本文并没有一句话具体介绍技术,它其实是提到了自己的主要贡献来达到介绍技术的作用。
2.5 主要贡献
✨ 我们提出了一个
✨ 我们提出了一个
✨ 我们的方法在各种分类任务中取得了先进的性能。
⭐论文方法
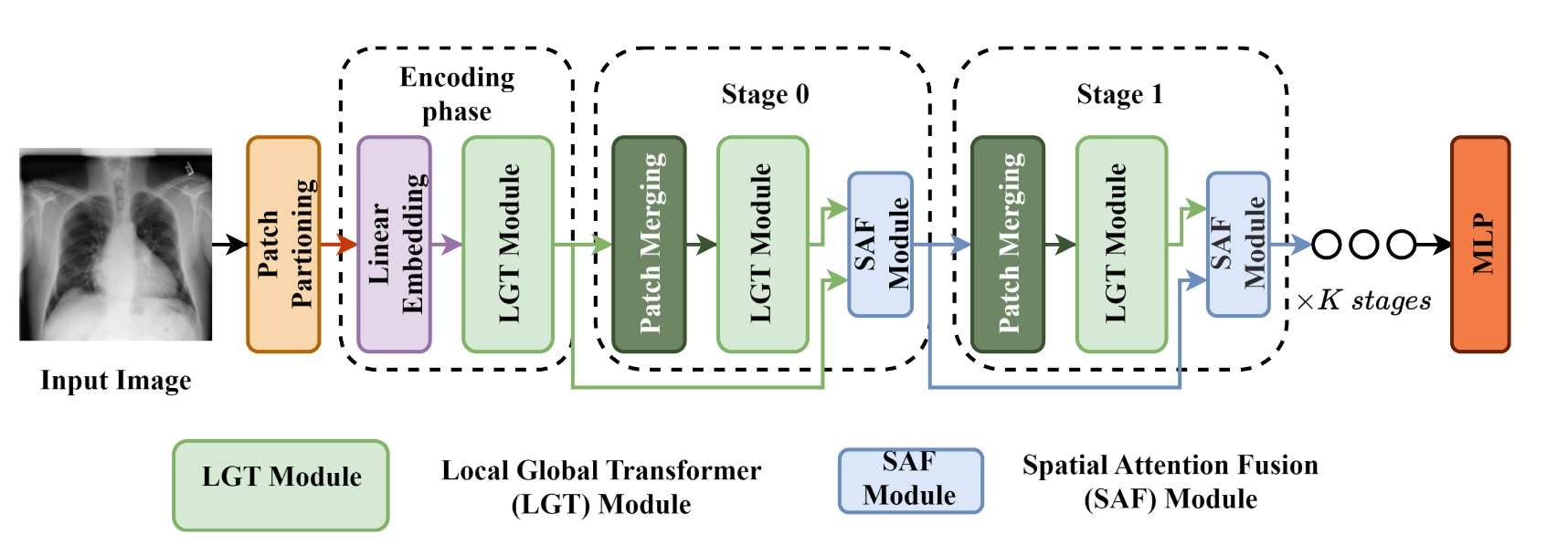
本文使用的技术架构与Swin-Transformer相似,并且中间很多模块直接也是使用的Swin-Transformer的模块,但是本文提出了两个新的模块,一个是Local-Global Transformer(LGT),另一个是Spatial Attention Fusion(SAF)。此架构分为三个部分:编码阶段(Encoding phase)和0阶段(Stage 0)和阶段1(Stage 1)。笔者大致梳理了一下这个架构,具体如下:
假设输入图像形状是$H \times W \times 3$,它将首先进行Patch partitioning,这是swin-transfomer的模块,它负责对图像分块,即分成若干个patch,假如要分成$N \times N$个patch,那么每个patch的大小就是$\frac{H}{N} \times \frac{W}{N}$,因此输出形状即$\frac{H}{N} \times \frac{W}{N} \times (N \times N \times 3)$。
进入编码阶段,这些patch将会被送入到Linear Embedding模块中,这里只是把$(N \times N \times 3)$嵌入到$d$维度中。即输出形状是$\frac{H}{N} \times \frac{W}{N} \times d$,再经过LGT模块进行全局局部特征提取后形状不变,仍然是$\frac{H}{N} \times \frac{W}{N} \times d$。
接着进入阶段0,首先进行Patch Merging下采样模块,这也是swin-transformer的模块,它输入的特征图。进行通道数加倍,空间尺寸减半的操作,即输出形状是$\frac{H}{2N} \times \frac{W}{2N} \times 2d$,然后经过LGT模块,形状不变,仍然是$\frac{H}{2N} \times \frac{W}{2N} \times 2d$。最后输入到SAF模块,整合编码层的输出特征和当前特征,形状不变,仍然是$\frac{H}{2N} \times \frac{W}{2N} \times 2d$。
最后进入K次阶段1,首先进行Patch Merging下采样模块,输出的特征图形状是$\frac{H}{4N} \times \frac{W}{4N} \times 4d$,然后经过LGT模块,形状不变,仍然是$\frac{H}{4N} \times \frac{W}{4N} \times 4d$。最后输入到SAF模块,整合编码层的输出特征和上一个stage的特征,形状不变,仍然是$\frac{H}{4N} \times \frac{W}{4N} \times 4d$。经过K次阶段1后,输出的特征图形状是$\frac{H}{N\times 2^{K+1}} \times \frac{W}{N\times 2^{K+1}} \times 2^{K+1}d$。
笔者:这里有很多模块,想要真正理解好,得先明白swin-transformer的内容,例如其中的Patch Merging和Patch Partitioning模块,这些模块都是swin-transformer的模块。Patch Partitioning为了将图像分块,达到transformer的输入要求,Patch Merging则是为了下采样,其类似于CNN中的卷积层+池化层。
3.1 Local-Global Transformer(LGT)模块
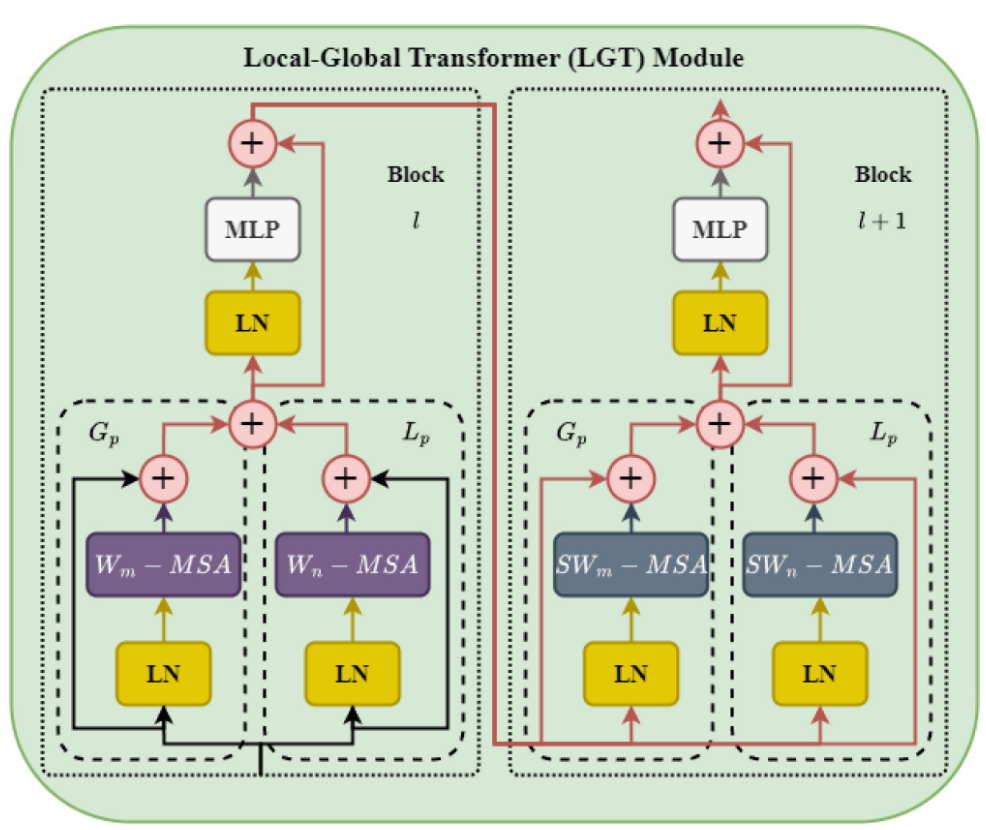
本图中仍然还是优化了Swin-Transformer的模块,图的左半部分Block $l$使用的就是swin-transformer提出的W-MSA(窗注意力机制),右半部分Block $l+1$使用的是SW-MSA(滑窗注意力机制)。
以左图为例,$W_m-MSA$和$SW_n-MSA$就是指利用窗长为$m$和$n$的注意力机制,$G_p$表示的是全局特征路径,$L_p$表示的是局部特征路径,因此要求$G_p$的窗长应该大于$L_p$的窗长,即$\color{red}m>n$。
此外需要注意的是,$W_m-MSA$和$SW_n-MSA$都是注意力机制,无论窗长是多少,输出的形状都保持不变,与输入形状相同,因此可以直接对$G_p$和$L_p$进行特征加和,这样就能够很好地整合局部和全局特征,而左半部分的输出即右半部分的输入。
LN表示层归一化层,MLP表示多层感知机,LGT中有多处残差连接,例如注意力机制的输出和LN输入,以及MLP的输出和LN输入,这样可以使得模型更加稳定,防止记忆丢失。
3.2 Spatial Attention Fusion(SAF)模块
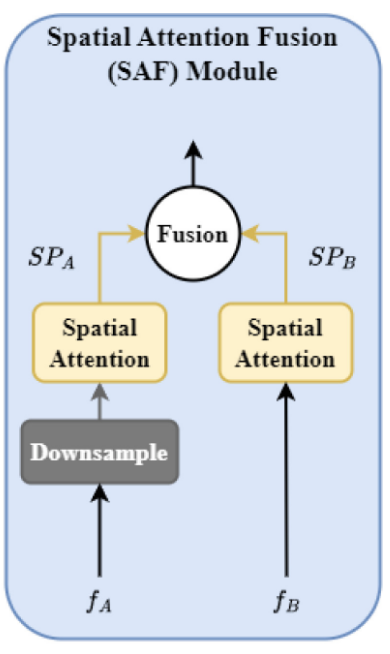
这个简单的模块就是作者所提的空间注意力融合模块,它的作用是整合上次阶段的输出和本阶段的输出,这样可以使得模型能够更好地传播重要信息,防止信息丢失。
它具体接收俩个输入$f_A$和$f_B$,$f_A$表示上阶段的输出,$f_B$表示本阶段的输出,根据前文对技术方案大图的介绍,由于$f_B$相比较$f_A$多经历了一次Patch Merging也就是下采样操作,导致形状不匹配。因此对于$f_A$,该模块要求先对它进行Downsample下采样操作使得形状匹配。之后对俩个特征分别进行空间自注意力机制(Spatial Attention),最后进行特征融合(Fusion)。最后输入到下一个阶段。
原文对模块的介绍很少,甚至都没有解释Spatial Attention是怎么计算的,笔者猜测Spatial Attention应该是一个现成的即插即用的模块。原文还没有具体介绍Fusion操作具体是怎么进行的,那么笔者就直接按照加和来理解了。
⭐实验设定
4.1 数据集与实验细节
本文将该方法运用到三个任务进行评估。任务和使用的数据集如下表:
| 任务 | 数据集 | 后文简称 | 评估指标 | 图片量(训练/测试) |
|---|---|---|---|---|
| 胸部疾病分类 | NIH Chest X-ray14 | Chest X | AUC | 86524/25596 |
| 皮损分类 | DermaMNIST | DM | ACC | 8010/2005 |
| 血细胞分类 | BloodMNIST | BM | ACC | 13671/3421 |
对于这三个数据集,通过交叉验证确定 Med-Former 的阶段数为 K = 3。该模型是通过最小化 400 个 epoch 的 CrossEntropy 损失来训练的,使用批量大小 16 和 0.001 的初始学习率。此外,学习率每 100 个 epoch 衰减 0.1 倍。所有实验均在具有 NVIDIA Tesla V100 GPU 上进行。
4.2 SOTA对比
进行了俩组实验,实验一是与基于transformer的方法进行对比,即与VIT和Swin-Transformer进行对比,实验二是与SOTA方法进行对比。实验一的结果如图:
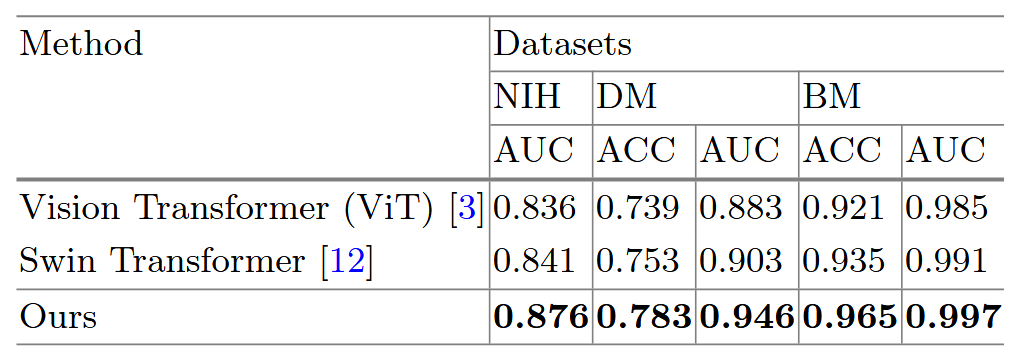
显然,所提方法在三个任务上的性能均优于 VIT 和 Swin-Transformer。第二组实验结果如图:
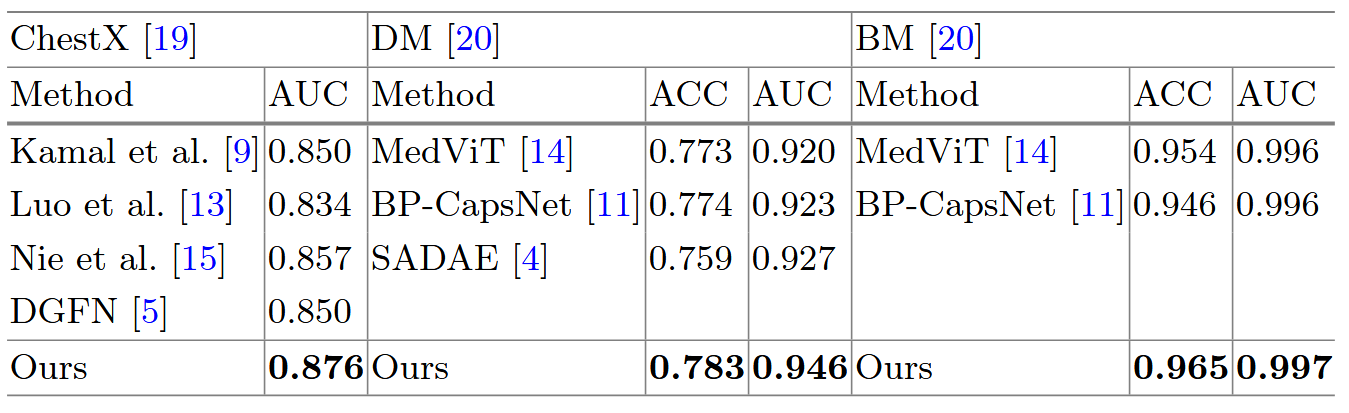
在这组实验中,Med-Former 在所有任务上均优于 SOTA 方法。
4.3 消融实验
作者设定了消融实验,主要是验证了LGT和SAF模块的有效性,实验结果如下:
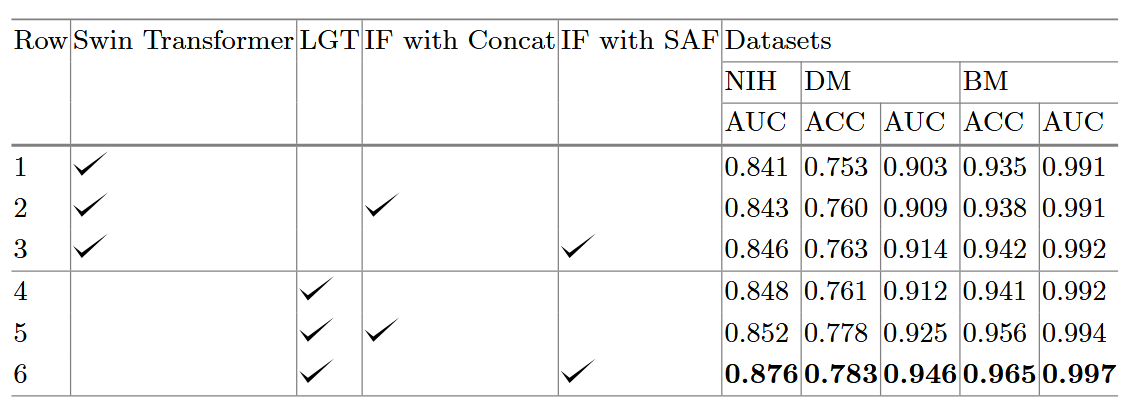
先看第一行,模型既没有使用LGT模块也没有使用SAF模块,只使用了Swin-Transformer的模块,这是最基础的版本。
第二行,模型使用了Concat操作来代替SAF模块,使用向量连接的手段进行阶段间特征融合,可以看到相比于第一行,性能提升,说明阶段间特征融合是有效的。
第三行,模型使用了SAF模块,可以看到相比于第二行,性能提升,说明SAF模块是更有效的阶段间特征融合方法。
再看第四行,模型使用了LGT模块,但不进行阶段间特征融合,可以看到相比于第一行,性能提升,说明LGT模块是有效的。
最后看第五行,模型使用了LGT模块和Concat模块,可以看到相比于第四行,性能提升。
最后看第六行,模型使用了LGT模块和SAF模块,也就是本文方法,可以是全部最优的。
文章还提供了注意力可视化热图,可以看到LGT模块和SAF模块的有效性,实验结果如下:
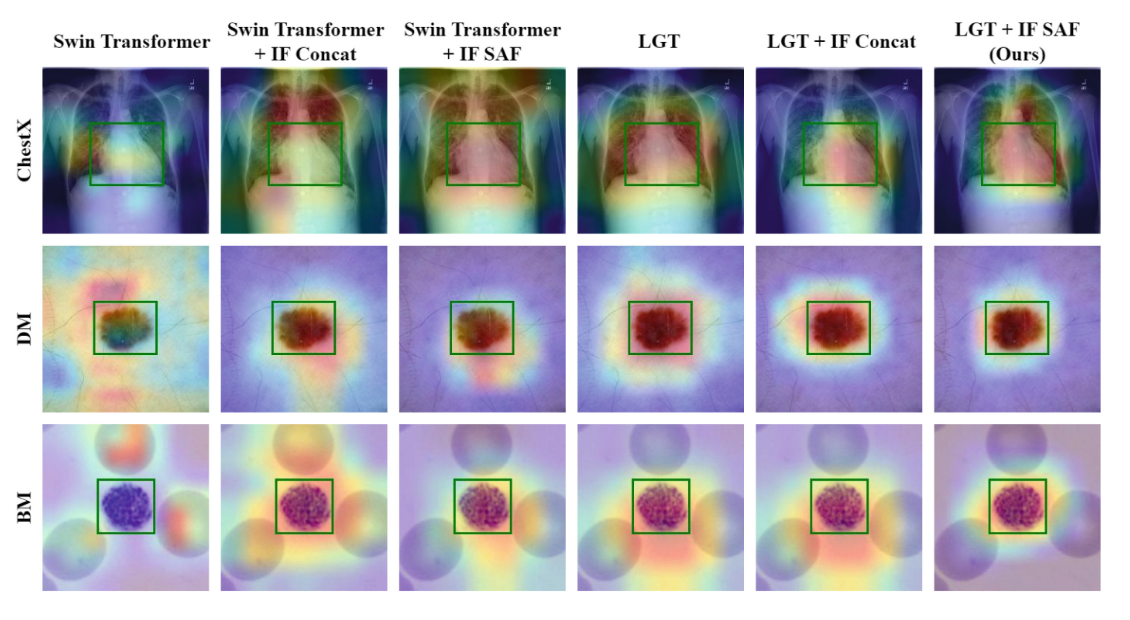
可以看出,加入各个模块的效果,其中我们的方法,可以精确地关注到重要的区域,这是其他方法所做不到的。(这个图,不要看框,看背景染色)
⭐笔者总结
这篇文章提出了一种更加有效的医学图像基于transformer特征提取方法。全文主要是对Swin-Transformer的改进,主要是提出了LGT和SAF模块,这两个模块的作用是局部全局特征融合和阶段间特征融合。然而感觉作者的语料不太充足,有些模块也没有介绍清楚。
但是本文提到的调整窗大小来进行多尺度特征融合确实是一个简单且有效的方案,也告诉我需要学一学swin-transformer的内容。







