
【论文阅读】:Med-2E3:A 2D-Enhanced 3D Medical Multimodal Large Language Model

⭐论文信息
1.1 拟解决的科学问题
✨ 本论文旨在构建一个适用于3D医学影像理解的多模态大模型,主要解决三维特征提取问题。
✨ 本文属于
⭐论文背景
2.1 摘要写作解读
- 第一句【挖坑一】:介绍3D医学影像分析的重要性,但在不同医学场景的通用性有限,现有的任务特定模型变得越来越不足。
- 第二句【填坑一】:多模态大模型(MLLMs)为这个挑战提供了一个有前途的解决方案。
- 第三句【挖坑二】:然而,现有的MLLMs在提取3维医学图像丰富、分层的信息方面仍然不足。
- 第四句【介绍本文方法】:受放射科医生同时关注3D结构和2D切片内容的实践启发,我们提出了、
Med-2E3 ,一个新的多模态大模型,同时利用了2D编码器和3D编码器。 - 第五句【填坑二】:为了更有效地聚合2D切片特征,我们设计了文本引导的切片间评分模块(
TG-IS )对每个2D切片进行注意力打分。 - 第六句【强调创新点】:据我们所知,Med-2E3是第一个同时集成3D和2D功能的医学影像分析的MLLM。
- 第七句【实验性能介绍】:在大规模开源3D医学多模态基准测试上表现好……
- 第八句【代码】:文章接收后会开源代码和模型。
2.2 挖坑
✨任务特定的模型很难处理复杂的多模态医学图像分析任务。
填坑:LLMs(大模型)在解决复杂的医疗多模态任务方面显示出广阔的潜力,为弥合模型研究和临床应用之间的差距提供了前景。
These models have shown promising potential in addressing complex medical multimodal tasks, offering the prospect of bridging the gap between model research and clinical application.
✨现有的医学MLLMs聚焦于2维图像,而很少研究3维图像…(中间作者在介绍为什么很少研究3维图像,因为没有现成可以用的3维图像编码器)3维图像编码器需要从头开始训练,表征能力有限。
As a result, 3D encoders must be trained from scratch on 3D medical images, which limits their representational capacity.
2.3 相关工作
3D医学图像分析
LLM出现之前:都是任务特定的模型,主要是面向医学图像分割或分类。
LLM出现之后:研究人员已经开始收集大规模 3D 医疗多模态数据集,用于3D医学多模态大模型训练和评估。长期以来,从 3D 图像中提取特征一直是 3D 医学图像分析中的一个挑战。以前的研究通常遵循以下两种方法之一。
【直接提取3D图像特征】:这种流派主张直接对3D图像进行提取特征,然而,由于3D医学图像的独特模态,这些编码器需要从头开始对3D数据进行训练,并且在捕获切片内细节方面往往无法达到通用域编码器的性能水平。
【2D逐切片聚合3D特征】:另一种方法涉及逐个切片提取特征,在聚合之前独立处理每个2D切片。虽然这种方法允许使用根据3D数据微调的预训练2D编码器,但它很难对3D图像中的切片间关系进行建模。
医学多模态大模型
医学MLLM的早期研究主要集中在2D医学图像上,而对3D医学图像的研究相对较少。
现有的3D医疗MLLM主要依靠3D编码器进行特征提取。这种单编码器设计在3D医疗多模态任务中无法实现与2D MLLM在2D多模态任务中相同的卓越性能。
2.4 一句话总结技术
我们提出了 Med-2E3,这是一种用于 3D 医学图像分析的新型MLLM,集成了3D和2D编码器。为了更有效地聚合2D特征,我们设计了一个文本引导的切片间 (TG-IS) 评分模块,该模块根据切片内容和任务说明对每个2D切片的注意力进行评分。
we propose Med-2E3, a novel MLLM for 3D medical image analysis that integrates 3D and 2D encoders. To aggregate 2D features more effectively, we design a Text-Guided Inter-Slice (TG-IS) scoring module, which scores the attention of each 2D slice based on slice contents and task instructions.
2.5 主要贡献
✨ 我们提出了Med-2E3,一种用于3D医学图像分析的新型MLLM。据我们所知,Med-2E3是第一款集成3D和2D编码器的3D医疗MLLM。
✨ 我们设计了一个文本引导切片间(TG-IS) 评分模块,以模拟放射科医生在3D医学图像分析中使用的注意力机制。该模块根据切片内容和任务说明对每个切片的注意力进行评分。
✨ 我们提出的 Med-2E3 在最大的3D医疗多模态基准测试中实现了最先进的性能。
⭐论文方法
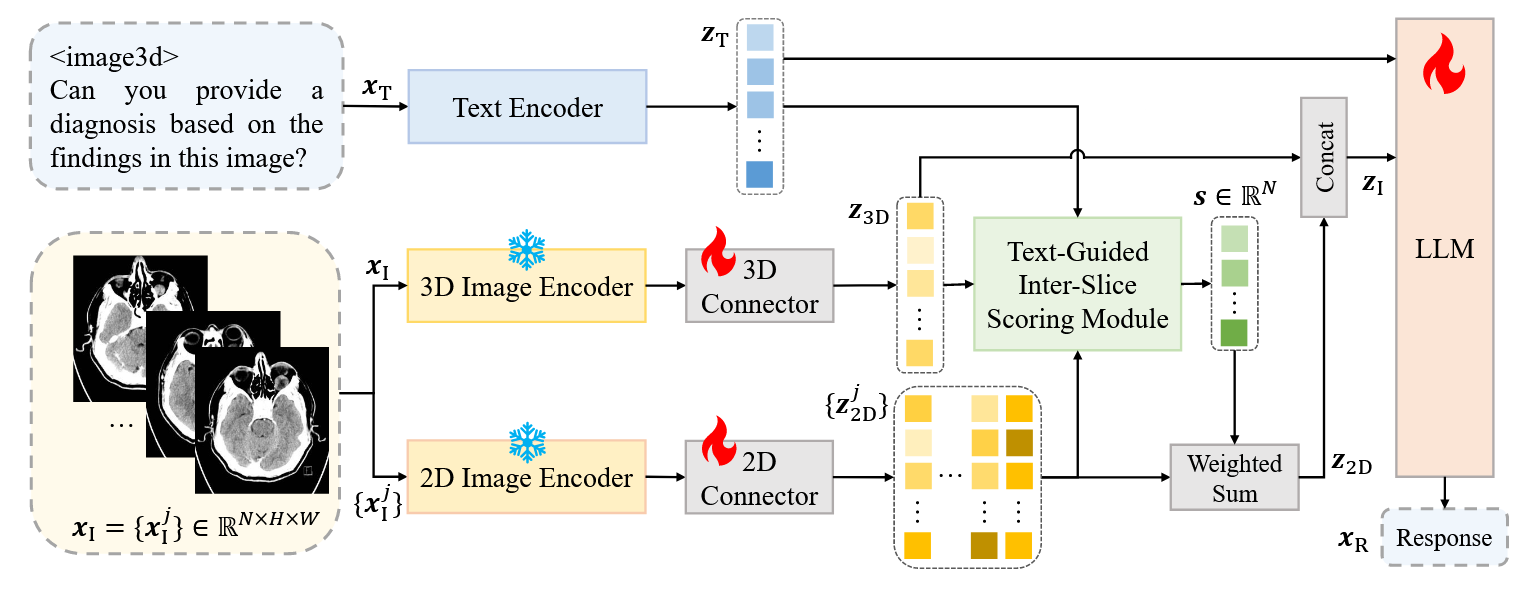
Med-2E3的输入有俩个,即3D医学影像$\boldsymbol{x_I}$和对应的文本问题$\boldsymbol{x_T}$,模型的输出是一个文本答案$\boldsymbol{x_R}$。模型的整体架构如上图所示。他们的形状即如下:
- 3D医学影像$\boldsymbol{x_I}=\{\boldsymbol{x_I}^j\}$:$N \times H \times W$:$N$表示切片数,$W$表示宽度,$H$表示高度。$\color{red}\{ \}$表示集合。
- 第j切片2D图像$\boldsymbol{x_I}^j$:$H \times W$
- 文本问题$\boldsymbol{x_T}$:文本。
- 文本答案$\boldsymbol{x_R}$:文本。
接下来,Med-2E3将分别对3维图像使用3D编码块、对逐个2维图像使用2D编码块(一个编码块包含一个编码器+连接器)得到对应特征表示$\boldsymbol{z_{3D}}$和$\{\boldsymbol{z_{2D}^j}\}$。尽管作者说$\boldsymbol{z_{3D}}$是一个一维的特征向量,在技术路线图也画成一维的形式,然而我多次推敲探究,按我的理解,其应该是一个二维矩阵,且形状是$L \times D$,这个形状也是作者自己写的,似乎与自己说的“一维的特征向量”的描述有所矛盾?因此按照我的理解,图中$\boldsymbol{z_{3D}}$中每一个色块不能当做一个标量值,而应该理解为一个长度为D的向量。因此,得到的特征表示$\boldsymbol{z_{3D}}$和$\{\boldsymbol{z_{2D}^j}\}$的形状分别是:
- 3D编码块输出$\boldsymbol{z_{3D}}$:$L_2 \times D$:$L_2$表示3D编码器的输出长度,$D$表示提取后的特征维度。
- 2D编码块输出$\{\boldsymbol{z_{2D}^j}\}$:$N \times L’ \times D$:$L’$表示2D编码器的输出长度。
- 第$j$切片2D编码块输出$\boldsymbol{z_{2D}^j}$:$L_2 \times D$
接着,初步提取的俩种特征将送入到
3.1 3D和2D编码块
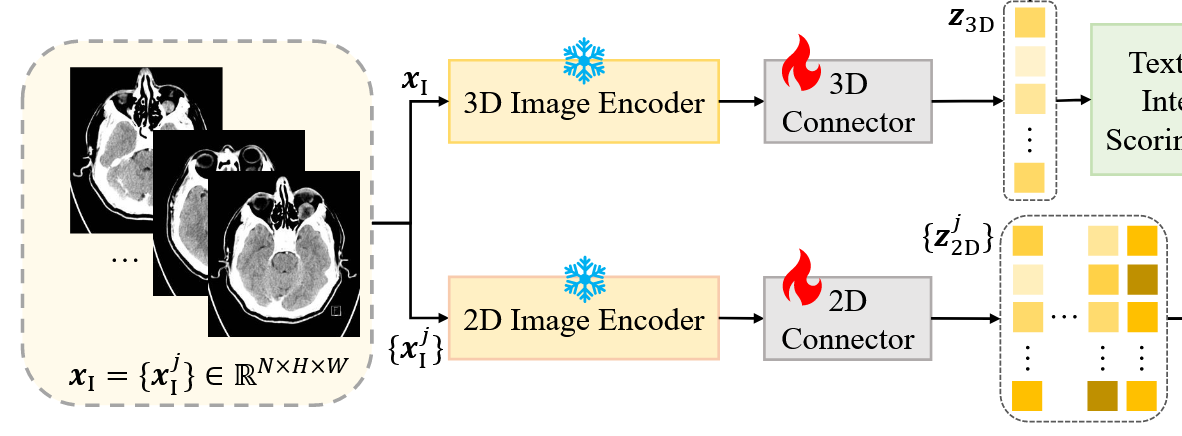
论文并没有详细介绍3D和2D编码块,经过我的研究,他们的工作机理应该如下描述:
【3D编码块】:
3D编码块包括一个冻结参数的3D编码器和一个可训练的3D连接器。3D编码器用于提取3D医学图像的特征,连接器用于下采样(池化)。3D编码块接收的输入是三维的3D医学图像$\boldsymbol{x_I}$,输出是3D特征(2维)$\boldsymbol{z_{3D}}$。
按照我的理解,本文使用的3D编码器是基于VIT的3D编码器,即将3D图像分割成若干个3D块(patch),然后将每个3D块展平为一个向量,最后将这些向量输入到VIT中进行处理。
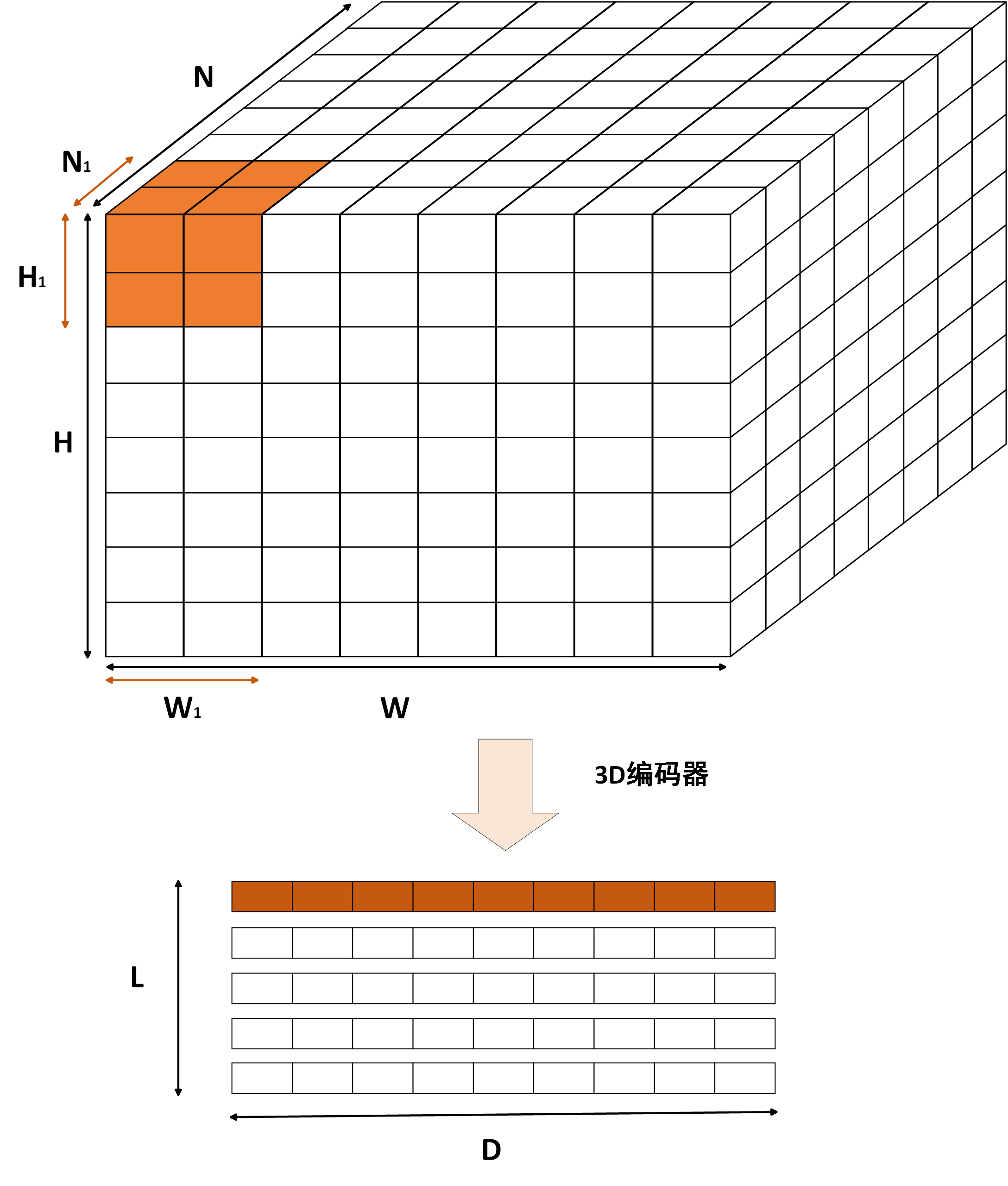
如上图,3D编码器的输入是3D医学图像$\boldsymbol{x_I} \in \mathbb{R}^{N \times H \times W}$,论文使用的3D编码器把该3D图像分割成若干patch,每个patch的大小即$N_1 \times H_1 \times W_1$,然后以patch为单位进行提取特征,简单的说,对于每一个patch,编码器就会输出一个D维向量表征其特征。那共有多少个patch呢?显然可以推算到一共有$L_1$个patch,$L_1$的计算公式如下:
接着,经过3D图像编码后,3D编码器会输出一个$L_1 \times D$的矩阵,表示每个patch的特征。接下来,连接器会对该矩阵进行下采样(池化),得到一个$L_2 \times D$的矩阵,$L_2$表示下采样后的长度。下采样的过程可以如图所示:
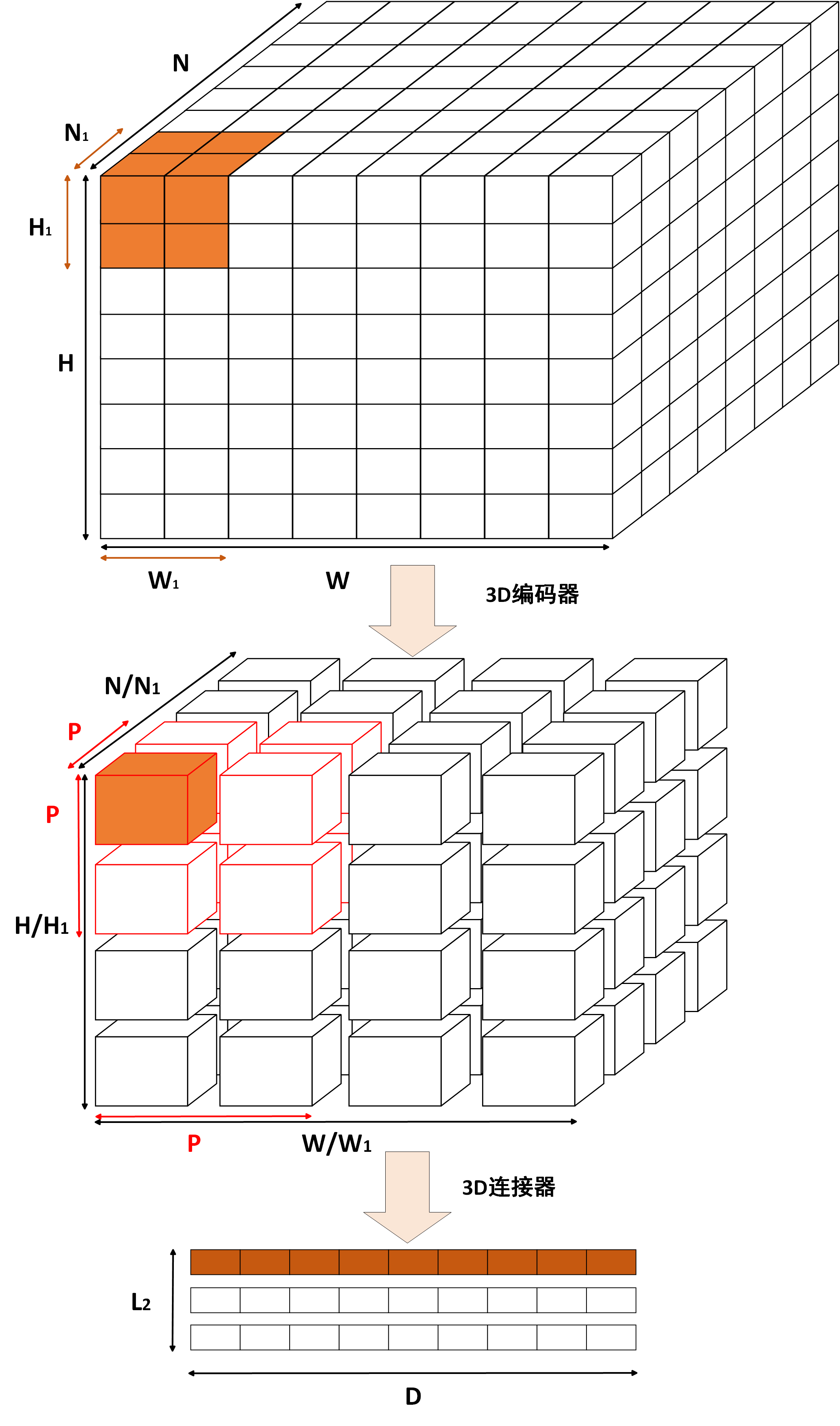
如上图所示,经过3D编码器后,3D医学图像$\boldsymbol{x_I}$会被分割成$L_1$个patch,输出特征即$L_1 \times D$的矩阵,图中即按照$L_1$个较大的矩阵块,每个较大的矩阵块对应$D$个特征。以平均池化为例,连接器会对每个较大的矩阵块进行平均池化,即选取$P \times P \times P$个patch取平均(对应图中的红色框线),这样每$P \cdot P \cdot P$个patch就会被池化成一个特征,最终得到$L_2$个特征。$L_2$的计算公式如下:
最终3D编码块的输出即表示为:
【2D编码块】:
2D编码块包括一个冻结参数的2D编码器和一个可训练的2D连接器。2D编码器用于提取2D医学图像的特征,连接器用于下采样(池化)。2D编码块接收的输入是二维的2D医学图像$\boldsymbol{x_I}^j$,输出是2D特征(3维)$\boldsymbol{z_{2D}^j}$。
整个过程如下图所示:
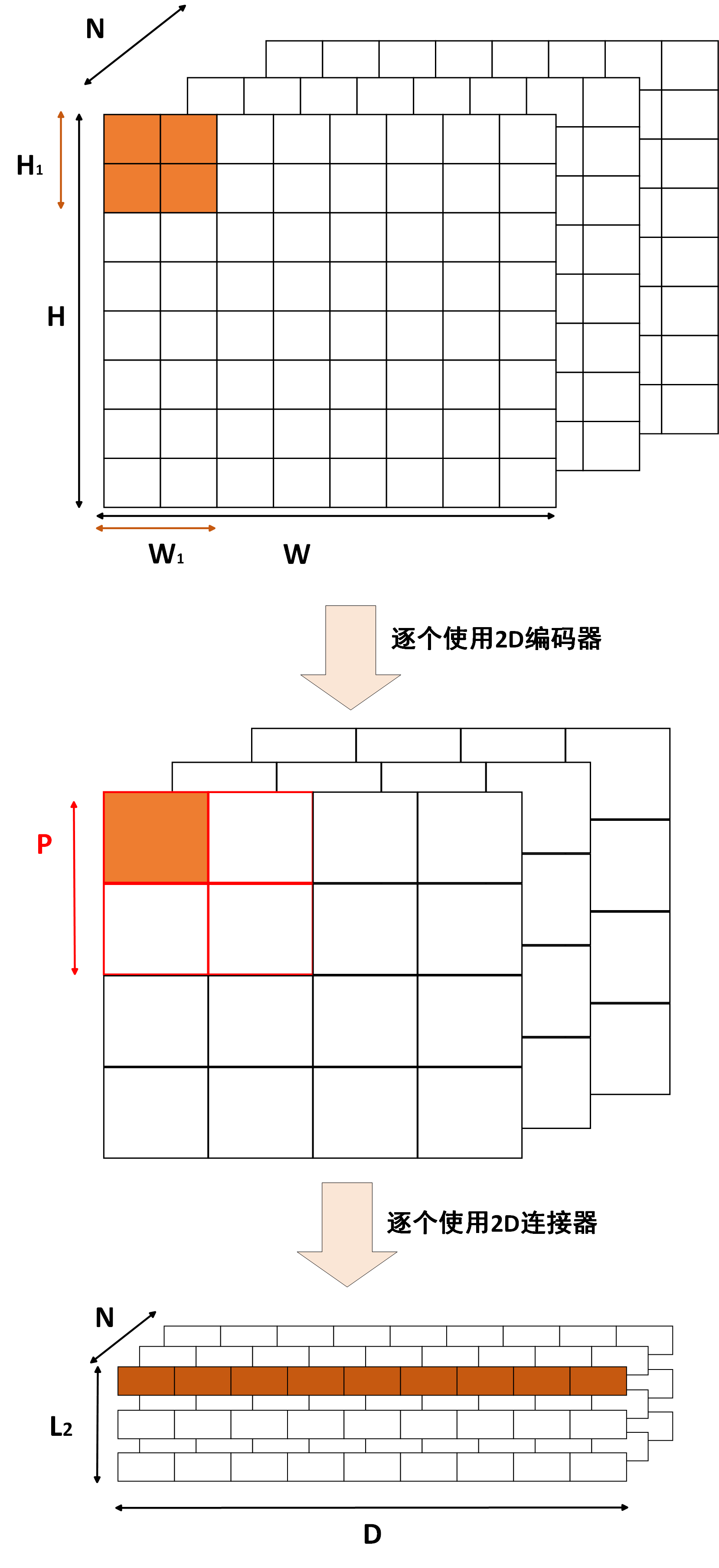
首先经过2D编码器后,每一张2D医学图像$\boldsymbol{x_I}^j$会被分割成$L_1$个patch,输出特征即$L_1 \times D$的矩阵,图中即按照$L_1$个较大的矩阵块,每个较大的矩阵块对应$D$个特征。接着,连接器会对该矩阵进行下采样(池化),最后得到一个$L_2$个特征。$L_2$的计算公式如下:
最终每一张图片在2D编码块的输出即表示为:
因此,2D编码块的输出集合为:
显然,这是一个三维的矩阵,与3D编码块的输出是一个二维的矩阵不同。
3.2 TG-IS模块
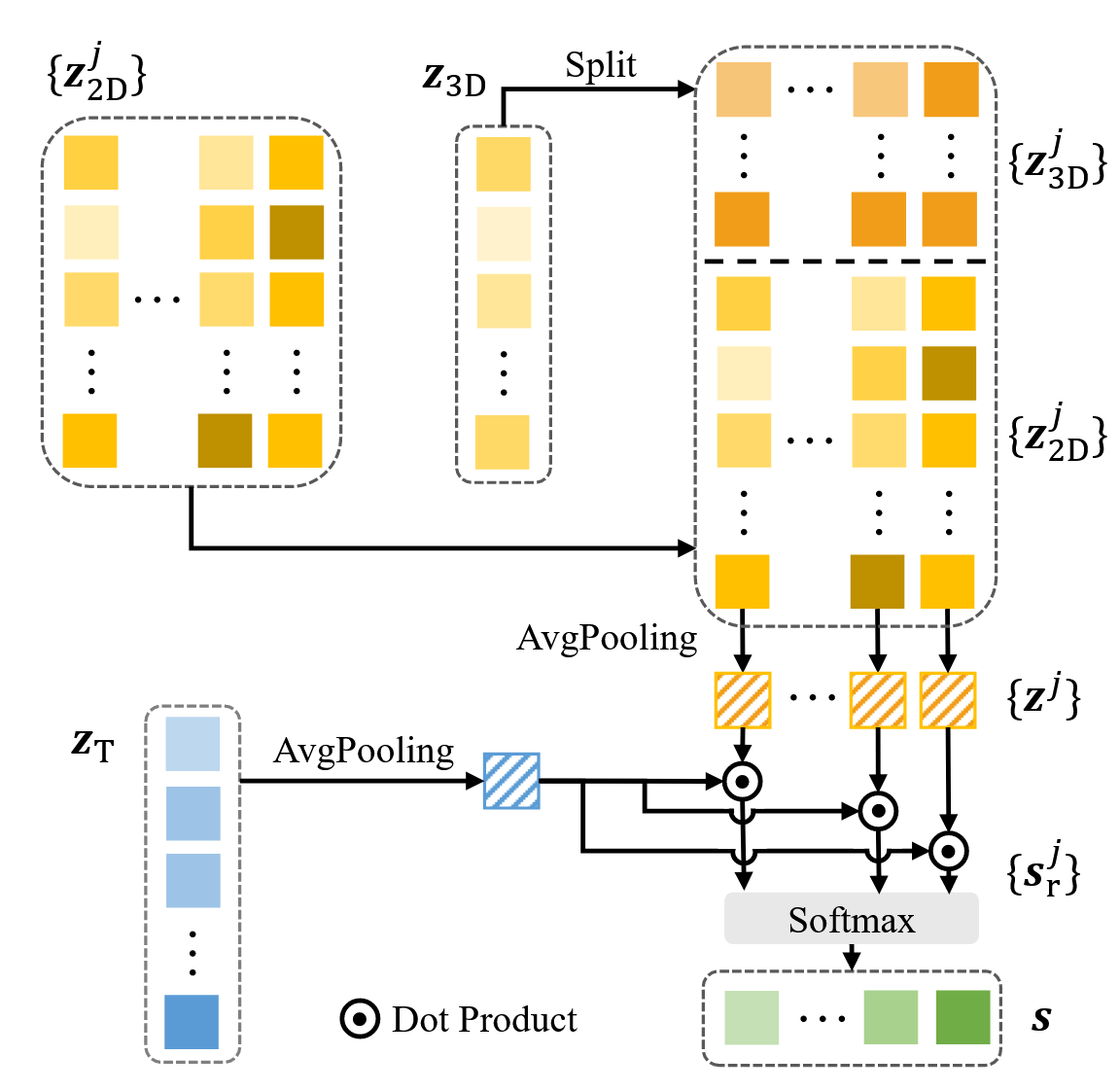
TG-IS模块的输入是2D编码块的输出$\{z_{2D}^j\}$和3D编码块的输出$z_{3D}$,输出是每个2D切片的注意力分数$\boldsymbol{s}$。该模块的原理即综合利用初步提取的3D特征$z_{3D}$和2D特征$\{z_{2D}^j\}$,对每个2D切片进行注意力评分。该模块首先将3D特征$z_{3D}$进行形状转换(对应图中的split)以将其转换为与2D特征$\{z_{2D}^j\}$同样三维的形状,接着对转换后的3D特征和2D特征进行拼接,最后将拼接后的特征与文本特征计算每个2D切片的注意力分数。该模块的输出即为每个2D切片的注意力分数$\boldsymbol{s}$,其形状为$N \times 1$,表示每个2D切片的注意力分数。
【形状转换】:
由于3D编码块的输出$z_{3D}$是一个二维的矩阵,而2D编码块的输出$\{z_{2D}^j\}$是一个三维的矩阵,因此需要对$z_{3D}$进行形状转换。首先我们知道初步的三维特征形状如下:
因此可以通过reshape函数将其转换为下面形状:
接着把第一维度$\frac{N}{N_1\cdot P}$进行复制$N_1\cdot P$次,并且交叉拼接起来(怎么交叉的,论文没有描述),即可以得到:
最后把第二维度和第三维度合并,即设定$L = \frac{H}{H_1\cdot P} \cdot \frac{W}{W_1\cdot P}$,最终得到的形状为:
【拼接】:
经过形状转换后,3D特征$z_{3D}$和2D特征$\{z_{2D}^j\}$的形状分别是$N \times L \times D$和$N \times L_2 \times D$,接下来对这两个特征进行拼接。拼接的方式是将3D特征$z_{3D}$和2D特征$\{z_{2D}^j\}$在第二维度上进行拼接,换句话说即对每一个$z_{3D}^j$和$z_{2D}^j$在第一维度上进行拼接。拼接后的特征形状为$N \times (L + L_2) \times D$,因此获得的特征拼接后的集合形状是$N \times (L + L_2) \times D$。
接下来,TG-IS模块会对拼接后的特征进行平均池化以消除第二维度$L + L_2$,得到一个$N \times D$的矩阵,整个过程即可描述为:
即第j个切片的综合特征为$\boldsymbol{z^j} \in \mathbb{R}^{D}$,所有切片的综合特征集合为$\{\boldsymbol{z^j}\} \in \mathbb{R}^{N \times D}$。
【注意力打分】:
什么叫做文本引导的切片间评分?简单来说就是模型输入的文本问题不同,模型对每个切片的注意力分数也不同。因此作者即利用文本的特征和每张2D切片的特征进行交互获得每张切片的注意力打分。具体来说,作者使用了一个文本编码器来提取文本问题的特征,文本编码器的输出是一个$L_T \times D$的矩阵,$L_T$表示文本编码器的输出长度。
同样地,对文本特征进行平均池化,即可以获得$\mathbb{R}^{D}$的特征。作者通过点积来逐个计算文本对每个切片的注意力即:
其中$\boldsymbol{s_r^j}$表示第j个切片的注意力分数,$\boldsymbol{z_T}$表示文本特征。最终所有切片的注意力分数集合为$\{\boldsymbol{s_r^j}\} \in \mathbb{R}^{N}$,接下来,按照打分的惯例,用softmax函数对注意力分数进行归一化处理,得到每个切片的注意力分数$\boldsymbol{s}$,即:
最终的注意力分数集合为$\boldsymbol{s} \in \mathbb{R}^{N}$。
3.3 2D特征增强3D特征
通过TG-IS,我们已经获得了每个切片的注意力分数$\boldsymbol{s}$,接下来我们需要利用该注意力分数来聚合2D特征$\{z_{2D}^j\}$,即使用加权求和:
接下来,用聚合后的2D特征与3D特征$z_{3D}$进行连接,即可以得到增强后的3D特征:
最后分别将问题文本特征$\boldsymbol{z_T}$和增强后的3D特征$\boldsymbol{z_I}$送入到LLM中进行处理,得到最终的文本答案$\boldsymbol{x_R}$。
⭐实验设定
4.1 数据集与实验细节
本文所使用的数据集来源于大规模3D医学多模态数据集,主要包含各种病变各种区域的CT影响。为了公平比较,作者只使用了数据集的标题和VQA数据。具体地数据集来源于M3D-Cap和M3D-VQA。数据集包含 120K 的3D CT图像和对应的标题或VQA数据。
VQA指的是视觉问答,即给定一张图片和一个问题,模型需要回答该问题。VQA数据集通常包含大量的图像和对应的问题-答案对,用于训练和评估模型在视觉问答任务上的性能。具体地,VQA可以分为开放式VQA和封闭式VQA。开放式VQA是指模型可以回答任何问题,例如“这张图片中有什么?”或“这张图片的主题是什么?”。封闭式VQA是指模型只能回答特定的问题,例如“这张图片中有多少个物体?”或“这张图片中的物体是什么颜色的?”,一般封闭式VQA是多选题的形式。
训练集分布:
- M3D-Cap:训练集包含 115K 标题数据。
- 部分M3D-VQA:用部分的VQA数据集进行微调,总共420K的开放式VQA数据和420K的封闭式VQA数据,封闭式VQA数据以多选题的形式进行训练。
测试集分布:
- M3D-Cap:测试集包含 2K 标题数据。
- M3D-VQA:测试集包含 13K的开放式VQA数据和13K的封闭式VQA数据,封闭式VQA数据以多选题的形式进行测试。
此外,本文终于介绍本文使用的3D编码器和2D编码器,作者使用了M3D-CLIP作为3D编码器,使用了SigLIP作为2D编码器。用Phi-3作为文本编码器。
4.2 SOTA对比实验
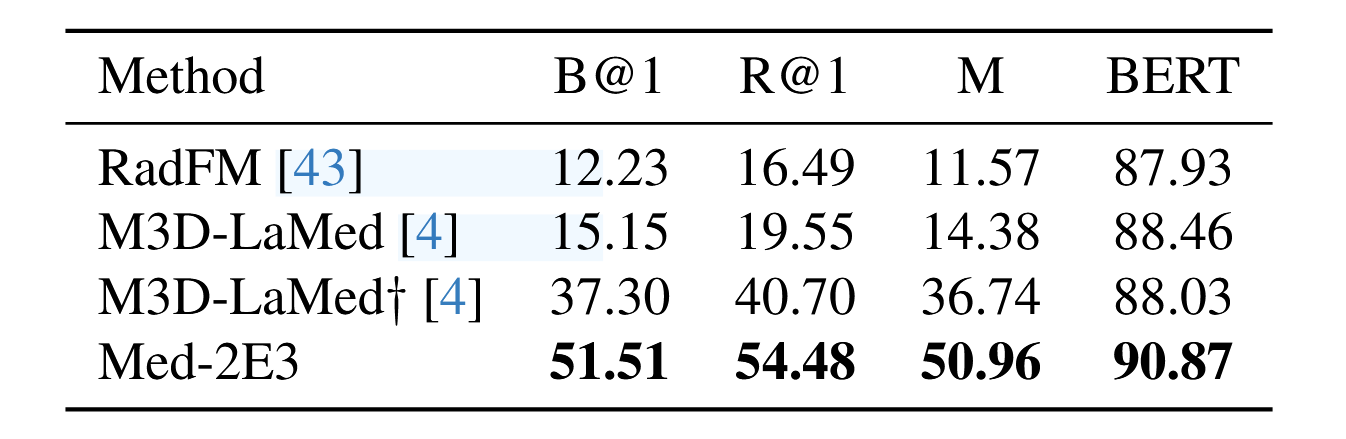
作者分别在M3D-Cap和M3D-VQA上进行对比实验,本文的对比实验主要是与现有的医学MLLM进行对比。在M3D-Cap上,作者与现有的医学MLLM进行对比,结果如下表所示:
在M3D-VQA上,作者与现有的医学MLLM进行对比,结果如下表所示:
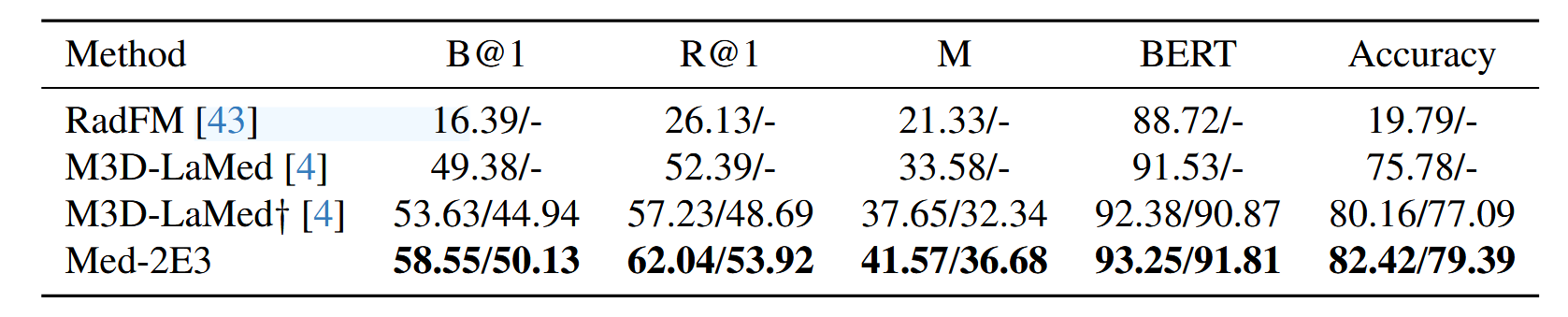
可以看出,本文的Med-2E3在M3D-Cap和M3D-VQA上均取得了最好的结果,其中†表示该实验结果是通过开源代码复现的,没有该标记则直接使用别人的实验数据。
4.3 消融实验
✨不同特征提取方法的消融实验
为了验证本文2D增强3D特征提取的有效性,作者设计了一个消融实验,分别使用不同的特征提取方法,即分别选择是否使用3D编码器和2D编码器进行特征提取。实验结果如下表所示:
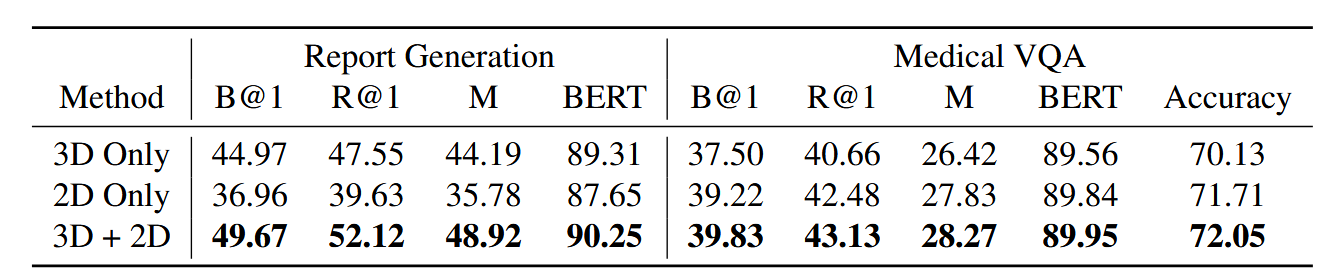
表中可以看出,综合使用了3D编码器和2D编码器进行特征提取的Med-2E3在报告生成和医学VQA俩个任务上都取得最好的性能。此外,表中还有俩个现象。其一是在报告生成任务上只使用3D编码器和效果要优于只使用2D编码器的效果;其二是,在医学VQA任务上只使用2D编码器的效果要优于只使用3D编码器的效果。作者认为前者是因为本文使用的3D编码器预训练时接受的是医学报告类似的数据,所以在报告生成任务上效果更好,而后者是因为VQA任务比较简单,2D编码器在自然图像中预训练,其足够鲁棒到处理医学VQA任务。
✨不同切片间评分方法的消融实验
为了验证本文设计的TG-IS模块的有效性,作者设计了一个消融实验,分别使用不同的切片间评分方法,具体地,作者设计的消融实验有三种选择:1)是否使用文本引导(文本编码器),如果不使用文本编码器,则直接对2D增强后的3D特征进行线性映射获得切片注意力分数。2)是否使用3D编码器的特征。3)是否使用2D编码器的特征。实验结果如下表所示:
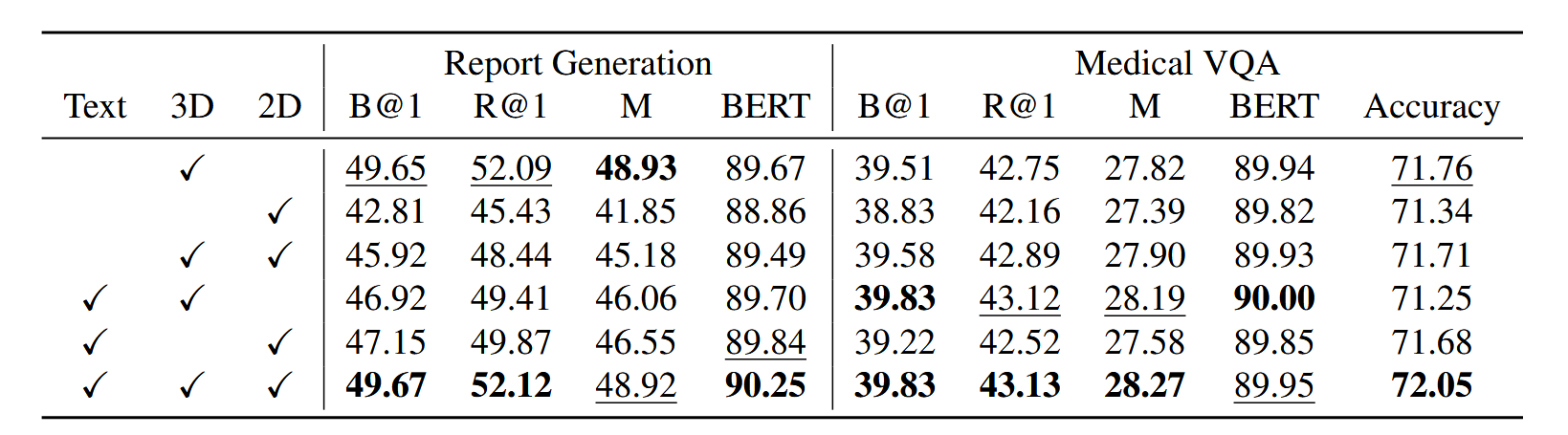
表中看到,本文提出的TG-IS模块(即3个特征都使用)的性能要优于其他评分方案。作者还补了一句:“尽管表中发现似乎3D特征稍微重要一点,但并不能始终认为到底是3D特征重要还是2D特征重要”,本实验验证了TG-IS模块的有效性。
4.4 可视化实验
作者最后设计了案例实验,来说明自己方法的有效性,并增加了文章的趣味性。
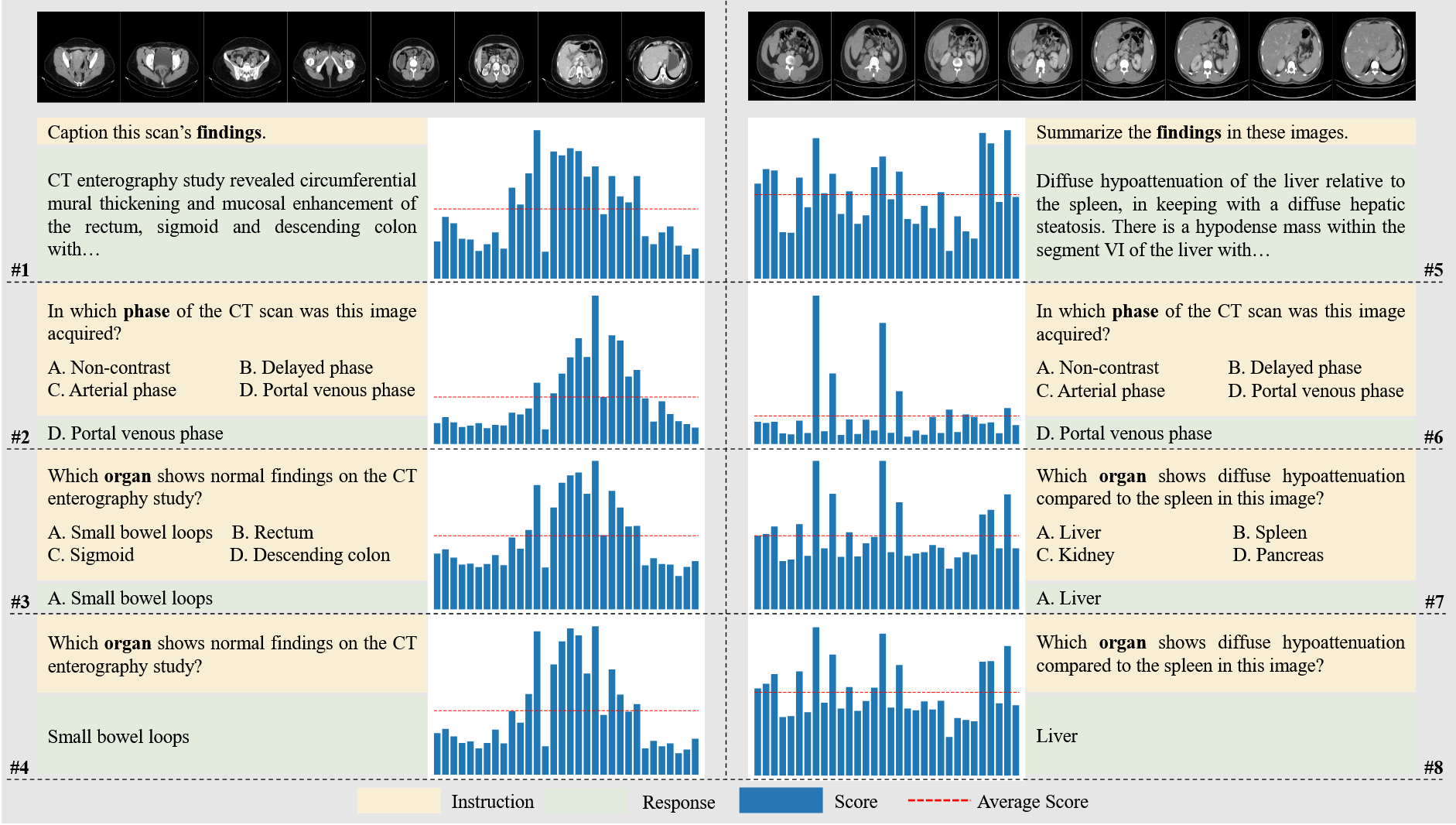
首先比较问题1和问题5,或比较问题2和问题6,我们发现相同的问题在不同的CT图像中,模型对每张切片的注意力分数分布是显著不同的,这说明图像特征多样性在TG-IS评分模块中的作用。
比较问题1和问题2,或比较问题5和问题6,我们发现相同的CT图像在不同的问题中,模型对每张切片的注意力分数分布是显著不同的,这说明表示注意力分数由任务说明指导,与我们的设计一致。。
比较问题3和问题4,或比较问题7和问题8,我们发现尽管问题的格式不一样(一个是开放式VQA,一个是封闭式VQA),但是模型对每张切片的注意力分数分布是显著相似的,这说明使用AvgPool对文本特征池化有效地提取了文本的特征。
有一些问题的注意力分布比较尖锐,例如问题6;而也有一些问题的注意力分布比较平滑,例如问题8。作者说到这种差异主要来源于CT影响的不同或问题的不同,基本上不是由于问题的格式导致的。
⭐笔者总结
这篇文章为提取CT影响3D特征提供了一个新的思路,即2D增强3D特征,并且设计了一个TG-IS模块来对每个切片进行注意力评分,来模拟放射科医生的思维过程。但是实际上,这篇文章在技术上描述地模棱两可,让人直接看论文理解有些困难。此外,作者在3D特征形状变换时利用了一些复制的手段,这一部分,应该还有改善的空间。






