
【论文阅读】:Semantic-Aware Representation Blending for Multi-Label Image Recognition with Partial Labels
本论文在论文分享会中分享,点击查看论文PPT 👆

⭐论文信息
⭐Abstract
第一句话:介绍本文的研究任务:用部分标注的标签去训练多标签分类模型时一个极具挑战性和实际性的任务。
第二句话:概括现有算法:为了解决这个问题,现有算法主要利用预训练模型或半监督模型为”unknown label(未发现标签)”生成伪标签。
第三句话:介绍现有方法的局限性:然而,这些方法需求足够多的”known label(已知标签)”来训练模型,因此在标签稀缺的情况下效果不佳。
第四句话:介绍本文的思路:为了解决这个问题,本文提出将“在不同图像中将类别特定(category-specific)的表征进行融合,将已知标签的信息传播到未知(未发现)标签中作为补充,进而避免对预训练模型的依赖”
第五句话:介绍本文的具体设计:具体来说,本文提出了一种语义感知的表征融合(Semantic-Aware Representation Blending, SARB)方法,通过俩个补充模型分别将实例级别(instance-level)和原型级别(prototype-level)的表征进行融合,从而补充未知标签。1)实例级别表征融合(ILRB):将一个图像中已知标签的表征融合到另外一个图像相应的未知标签中。2)原型级别表征融合(PLRB):为每个类别得到一个稳定的原型表征,在未知标签里融合相应的原型表征进行补充。
第六句话:介绍本文的实验结果:在多个公开数据集上进行的实验表明,本文的方法在各种标签发现率的设定下本文方法都要优于现有主要竞争对手,具体mAP提升了…
第七句话:给出开源代码
⭐Introduction
段落一:引入部分标注的多标签分类任务的重要性:多标签图像识别(MLR)旨在从输入图像中提取所有语义标签,相较于单标签任务,MLR是一个更具挑战性和实用性的任务。由于输入图像和输出标签空间的复杂性,收集具有完整多标签注释的大规模数据集非常耗时。为了解决这个问题,近年来的研究趋向于研究部分标签的多标签图像识别任务(MLR-PL),在该任务中,仅提供少数正标签和负标签(标注为1或-1),而其他标签未知(见图1,标注为0)。MLR-PL更贴近实际场景,因为它不要求每张图像都拥有完整的多标签注释。

段落二:介绍传统算法和现有算法的缺陷:传统算法:传统算法只是简单地忽略未知标签或者假定其为负标签,这样都会带来较差的性能,因为它们要么缺失了标注信息、要么引入了错误的标签。现有算法:最近工作提出先用已知标签数据训练出分类模型,并用此模型为未知标签生成伪标签。现有算法的缺陷(挖坑):尽管这些算法取得了令人印象深刻的进展,但它们依赖于足够的多标签注释来进行模型训练,如果将已知标签比例降低到很小的水平,它们的性能就会明显下降。
段落三:介绍本文方法思路:(介绍思路启发):在n图像中未知的标签c,可能在另外一张m图像是已知存在的,我们可以从m图像中提取标签c的信息,并将其融合到n图像中,这样就为n图像补充了未知的标签c。(单标签场景做法):先前有工作使用mixup算法将两张图像融合,生成一张包含两者语义信息的新图像,从而帮助正则化单标签识别模型的训练。单标签场景算法无法直接运用到多标签场景:然而,多标签图像通常包含多个语义对象分布在整张图像中,简单地将两张图像混合往往导致语义信息混乱。(本文SARB框架):我们设计了一个 语义感知的表征融合(SARB)框架,能够学习并融合类别特定的特征表示,用来补全未知标签。该框架不依赖于预训练模型,并且在已知标签比例不同的情况下都能保持稳定的性能。
段落四:具体介绍本文设计:具体来说,我们首先引入了一个类别特定表征学习(CSRL)模块,该模块利用类别语义来指导生成类别特定的表征。(类别解耦)。设计了一个实例级表征融合(ILRB)模块,用于将m图像中已知标签c的表征融合到另一张n图像中对应未知标签的表征上。这样一来,图像n也能包含标签的信息,从而实现标签补全。ILRB能够生成多样化的融合表征以提升性能,但过于多样化的表征可能导致训练不稳定。(PLRB的动机)。为了解决这一问题,进一步提出了原型级表征融合(PLRB)模块,用于为每个类别学习更鲁棒的表征原型,并将未知标签的表征与对应类别的原型进行融合。这样可以同时生成多样化且稳定的融合表征,用于补全未知标签。
段落五:总结本文贡献:贡献一:提出了一种语义感知的表征融合框架来补全未知标签,此框架不依赖预训练模型,在所有已知标签比例设置下表现稳定。贡献二:设计了实例级和原型级表征融合模块,可以生成多样且稳定的融合特征表征,以补全未知标签。贡献三:我们在多个大规模多标签识别(MLR)数据集上进行了广泛的实验,包括 Microsoft COCO、Visual Genome以及 Pascal VOC 2007,以验证所提出框架的有效性。我们还进行了消融实验,以深入分析每个模块的实际贡献。
⭐方法
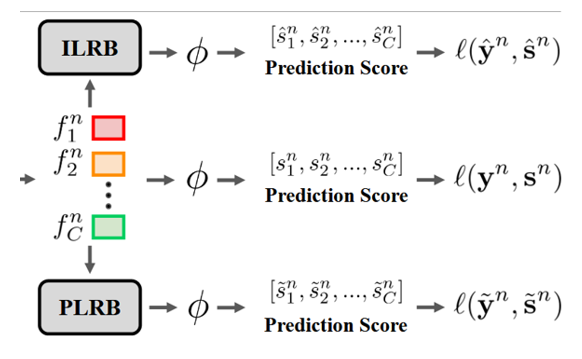
概述
给定一张输入图像$I_n$,先用主干网络(backbone)提取全局特征图$f^n$,接着引入 类别特定表征学习(CSRL)模块 $\phi_{csrl}$生成类别特定的表征$[f_1^n, f_2^n, …, f_C^n]$,其中C是类别数。然后,设计了实例级表征融合(ILRB)模块和原型级表征融合(PLRB)模块,分别将类别特定表征进行融合,生成补全未知标签的融合表征。最后,将三种不同表征(原始表征、实例表征融合后、原型表征融合后)输入到分类器$\phi$(GNN+线性分类器+sigmoid)预测出各类别的分数,最后用交叉熵损失函数进行训练。
backbone和CSRL
类别特定表征学习(CSRL)模块。即根据语义类别从一张多标签图像中提取出对应类别的特征表示,并将其作为类别特定的表征。具体来说,给定一张输入图像$I_n$,先用主干网络(backbone)提取全局特征图$f^n$,接着引入 类别特定表征学习(CSRL)模块 $\phi_{csrl}$生成类别特定的表征$[f_1^n, f_2^n, …, f_C^n]$,其中C是类别数。这种设计的初心是:一张多标签图像散落了多个语义对象在图像的不同位置,直接使用全局特征图往往会混淆不同类别的语义信息。CSRL模块通过引入类别语义信息来指导类别特定表征的生成,从而实现类别解耦,根据不同类别提取图像中相应的特征。
backbone可以简单的使用一些预训练的卷积神经网络(CNN),如ResNet、VGG等,来提取图像的低级特征。然后,CSRL模块在此基础上进行进一步的特征学习,以获得更具语义信息的类别特定表征。CSRL模块也可以通过不同的现成算法实现,例如语义解耦(chen et al. 2019b)或语义注意力机制(Ye et al. 2020)等。
实例级表征融合(ILRB)模块
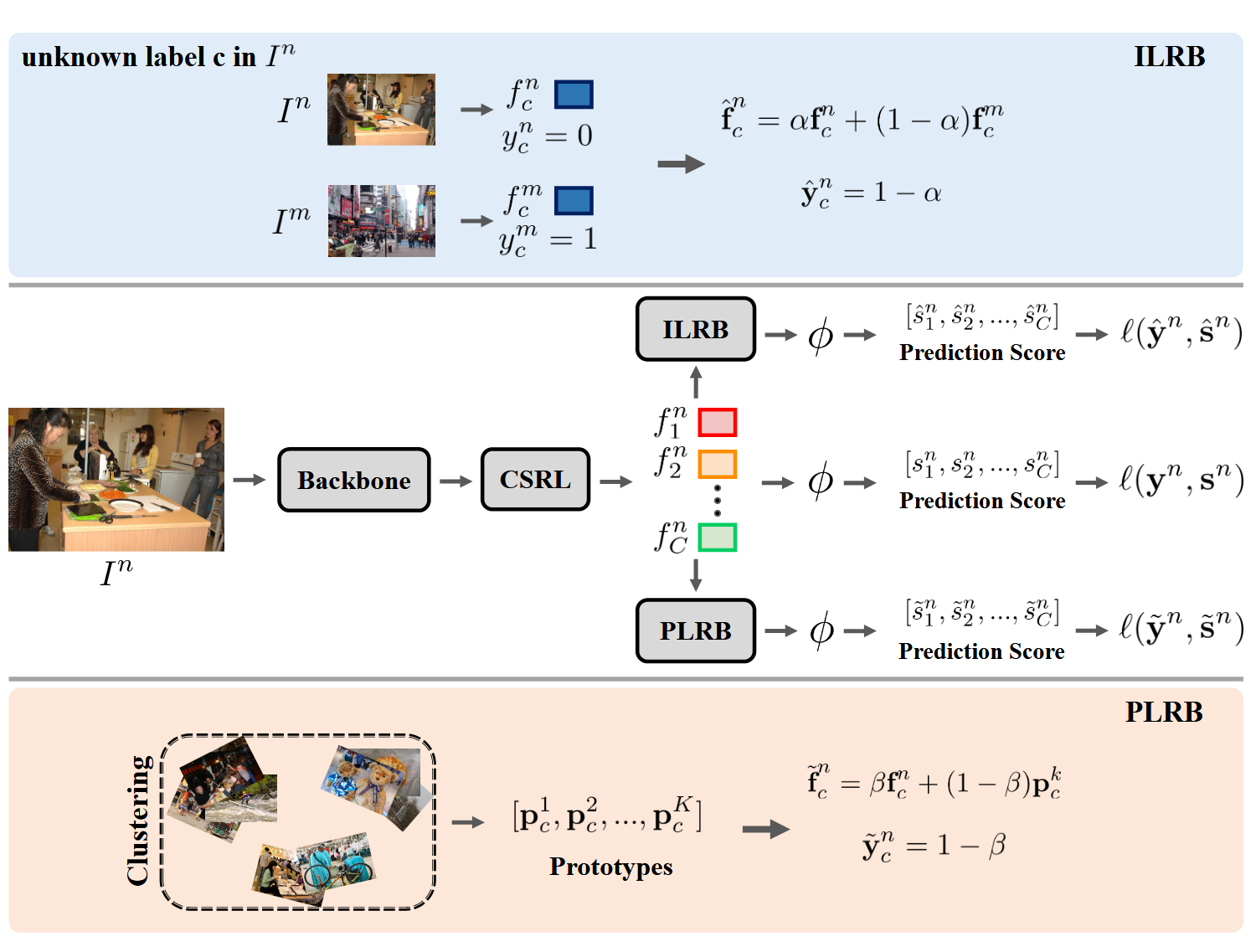
动机:直观地说,图像 $I_n$中的未知标签 $c$ 可能在另一幅图像 $I_m$ 中是已知的。ILRB 模块的目的是将图像 $I_m$ 中标签 $c$ 的信息融合到图像 $I_n$ 中,从而使图像 $I_n$ 也能拥有已知标签 $c$。为了实现这一目的,我们融合了属于同一类别的不同图像的表征,将一幅图像的已知标签转移到另一幅图像的未知标签上。
给定俩张训练图像$I_n$和$I_m$,它们分别有:语义特征向量(CSRL后的表征):$[f_1^n, f_2^n, …, f_C^n]$和$[f_1^m, f_2^m, …, f_C^m]$。其中,$f_i^n$表示图像$I_n$中类别$i$的特征表示,$f_i^m$表示图像$I_m$中类别$i$的特征表示,同样地,它们还有标签向量:$y^n = \{y_1^n, y_2^n, …, y_C^n\}$和$y^m = \{y_1^m, y_2^m, …, y_C^m\}$。接下来ILRB将通过融合俩个图像的语义表征和标签,补全未知标签。
现在假设图像 $I_n$ 中类别 $c$ 的标签是未知的,而图像 $I_m$ 中类别 $c$ 的标签是已知的,即$y_c^n = 0$和$y_c^m = 1$。此时就可以把$m$图像中类别$c$的表征$f_c^m$融合到图像$n$中类别$c$的表征$f_c^n$上,从而生成补全未知标签$c$的融合表征$f_{c}^{n}$。具体来说,其分为语义表征融合和标签融合俩部分:
标签融合如下:
其中$\alpha \in [0, 1]$是一个超参数,用于控制融合表征中原始表征和补充表征的比例。初始值$\alpha=0.5$。通过这种方式,ILRB模块能够将图像$m$中已知标签$c$的信息有效地传递到图像$n$中,从而实现对未知标签的补全。
原型级表征融合(PLRB)模块
动机:虽然 ILRB 模块可以明显提高性能,但它可能会干扰训练过程,因为它会生成许多不同的融合表示进行训练,尤其是当已知标签比例较低时。针对这一问题,我们进一步设计了一个 PLRB 模块,该模块通过学习为每个类别生成更稳定的表示原型,并将图像 $I_n$ 中未知标签的表示与相应类别的原型进行融合。
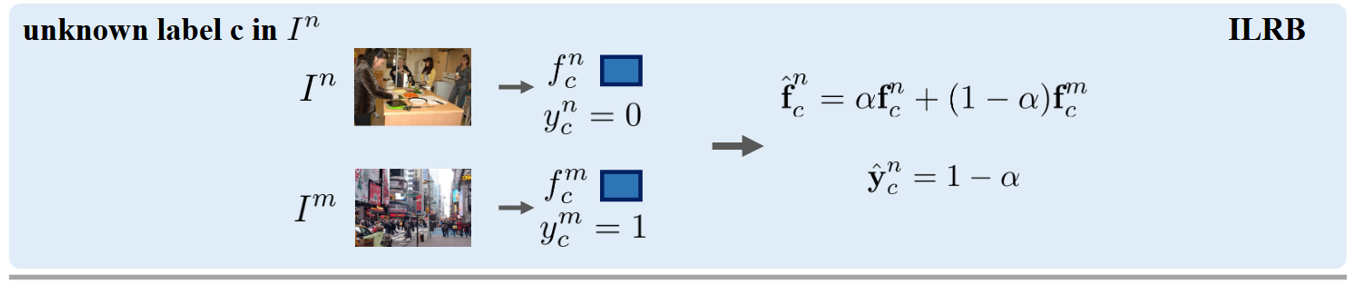
原型即用于描述每个类别的整体表征(类似于得到一个类别的代表特征),具体地,对于类别$c$,其做法如下:
1、首先收集所有含有已知标签$c$的图像。
2、使用CSRL提取这些图像的类别表征,得到向量集合:$[f_c^1, f_c^2, …, f_c^{N_c}]$,其中$N_c$是含有已知标签$c$的图像数量。
3、使用K-means聚类将这些特征向量聚类为$K$个原型:$P_c = \{p_c^1, p_c^2, …, p_c^K\}$。
接下来为了学习更加稳定的原型,应该设计一个损失:同一类别的表征应该彼此接近,不同类别的表征应该远离。因此,定义对比损失如下:若俩张图像$I_n$和$I_m$都含有已知标签$c$,则它们的类别表征$f_c^n$和$f_c^m$应该彼此接近,即提高余弦相似度。否则,减小余弦相似度,因此损失定义如下:
总对比损失即:
通过上述步骤,即可以学习到一个较为稳定的类别原型,接下来进行原型级别的融合表征:给定一张输入图像$I_n$,其表征向量为$[f_1^n, f_2^n, …, f_C^n]$,标签向量为$y^n$。先选择一个未知标签$c$($y_c^n=0$),然后从类别$c$的原型集合$P_c$中随机选择一个原型$p_c^k$,将其融合到图像$I_n$中类别$c$的表征$f_c^n$上,从而生成补全未知标签$c$的融合表征$\tilde{f}_c^n$。具体也分为表征融合和标签融合俩部分:
其中$\beta \in [0, 1]$是一个超参数,用于控制融合表征中原始表征和补充表征的比例。初始值$\beta=0.5$。通过这种方式,PLRB模块能够将原型信息有效地传递到图像中,从而实现对未知标签的补全,并保证了训练的稳定性。
优化方案
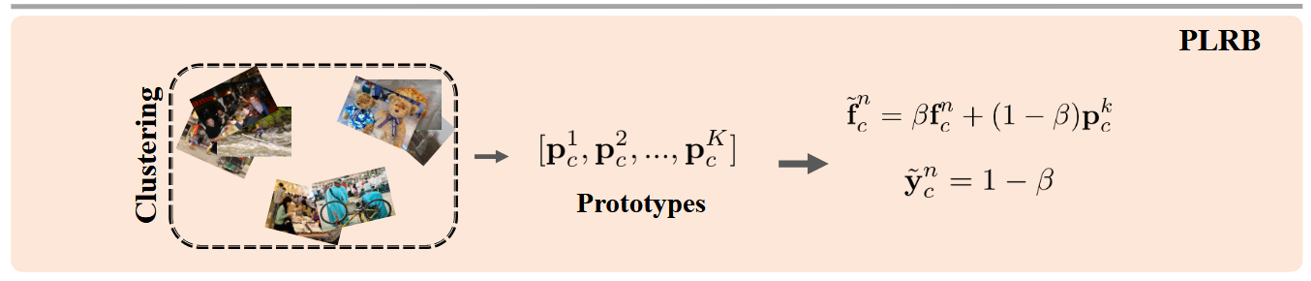
综合以上模块,对于一张训练图像$I_n$,经过backbone和CSRL模块,得到类别特定表征$[f_1^n, f_2^n, …, f_C^n]$,对于特定类别$c$,其有三种不同的表征:1):原始表征:$f_c^n$;2):实例级融合表征:$\hat{f}_c^n$;3):原型级融合表征:$\tilde{f}_c^n$。将这三种表征分别输入到分类器$\phi$中,得到对应的预测分数:$s_c^n = \phi(f_c^n)$,$\hat{s}_c^n = \phi(\hat{f}_c^n)$,$\tilde{s}_c^n = \phi(\tilde{f}_c^n)$。(如图所示)然后,使用交叉熵损失函数计算每种表征的分类损失。
按照已有工作,本文采用部分二元交叉熵损失(partial binary cross entropy loss) 作为监督网络的目标函数。具体来说,给定预测的概率得分向量$s^n = \{s_1^n, s_2^n, …, s_C^n\}$和标签向量$y^n = \{y_1^n, y_2^n, …, y_C^n\}$,则部分二元交叉熵损失定义如下:
其中,$\mathbb{1}_{\{y_c^n = 1\}}$是指示函数,当$y_c^n = 1$时取1,否则取0;$\mathbb{1}_{\{y_c^n = -1\}}$同理,简单来说,部分二元交叉熵损失只考虑正负标签的贡献,而忽略未知标签的影响。
同样地,本文采用该损失监督ILRB和PLRB模块,即$\mathcal{l}(\hat{y}^n, \hat{s}^n)$和$\mathcal{l}(\tilde{y}^n, \tilde{s}^n)$。最终的总损失函数定义如下:
最后将分类损失和对比损失结合,获得最终的损失函数:
其中,$\lambda$是一个超参数,用于平衡分类损失和对比损失的权重。由于$L_{cst}$通常远大于$L_{cls}$,因此可以将$\lambda$设置为一个较小的值,例如0.05。
⭐Experiments
实施细节
为了公平比较,我们采用 ResNet-101 作为主干网络提取全局特征图,并用在 ImageNet 数据集上预训练的参数初始化,同时随机初始化新增层的参数。训练时,前 91 层 ResNet-101 的参数固定,其他层采用端到端的方式训练。
🏋️♂️ 训练过程
| 项目 | 设置 |
|---|---|
| 优化器 | Adam |
| 批大小 | 16 |
| 动量 | 0.999 和 0.9 |
| 权重衰减 | $5 \times 10^{-4}$ |
| 初始学习率 | $1 \times 10^{-5}$(每 10 个 epoch 降低 10 倍) |
| 总轮数 | 20 epoch |
📈 数据增强
| 步骤 | 描述 |
|---|---|
| 1 | 输入图像缩放到 $512 \times 512$ |
| 2 | 随机选择 $\{512, 448, 384, 320, 256\}$ 作为裁剪大小 |
| 3 | 裁剪后再缩放到 $448 \times 448$ |
| 4 | 随机水平翻转 |
⚙️ 训练策略
| 时间点 | 策略 |
|---|---|
| 从第 5 个 epoch 开始 | 使用 ILRB 和 PLRB 模块 |
| 每隔 5 个 epoch | 重新计算各类别的原型 |
🔎 推理阶段
| 项目 | 设置 |
|---|---|
| 模块 | 移除 ILRB 和 PLRB |
| 输入 | 图像统一调整为 $448 \times 448$ |
数据集
我们在 MS-COCO (Lin et al. 2014)、Visual Genome (Krishna et al. 2016) 和 Pascal VOC 2007 (Everingham et al. 2010) 上进行实验,用于公平对比。
| 数据集 | 类别数/描述 | 训练集 | 验证/测试集 | 备注 |
|---|---|---|---|---|
| MS-COCO | 80 个日常生活类别 | 82,801 张图像 | 40,504 张图像 | |
| Pascal VOC 2007 | 20 个类别 | - | 9,963 张图像 | |
| Visual Genome | 80,138 个类别 | 98,249 张图像 | 10,000 张图像 | 选取 200 个最常见类别构建 VG-200 子集 |
| VG-200 | 200 个类别 | 该划分将公开供进一步研究 |
实验设定
所有的数据集均具有完整标注。为了模拟部分标注,参考前人工作 (Durand et al. 2019; Huynh & Elhamifar 2020):随机丢弃部分正负标签,制造“部分标注”数据集。在这项工作中,丢弃标签的比例从 90% 到 10% ,因此已知标签的比例为 10% 到 90%。为了进行公平的比较,我们采用了所有类别的平均精度(mAP)来评估不同比例的已知标签。为了进行更全面的评估,我们还计算了所有比例的平均 mAP。此外,我们还遵循之前大多数 MLR 作品(Chen 等人,2019b)的做法,采用整体(overall)和每类(per)精度、召回率、F1-measure(即 OP、OR、OF1、CP、CR 和 CF1)进行更全面的评估。
SOTA对比实验系列
为了评估所提出的 SARB 框架的有效性,我们将其与传统的 MLR 算法和当前的 MLR-PL 算法进行了比较。
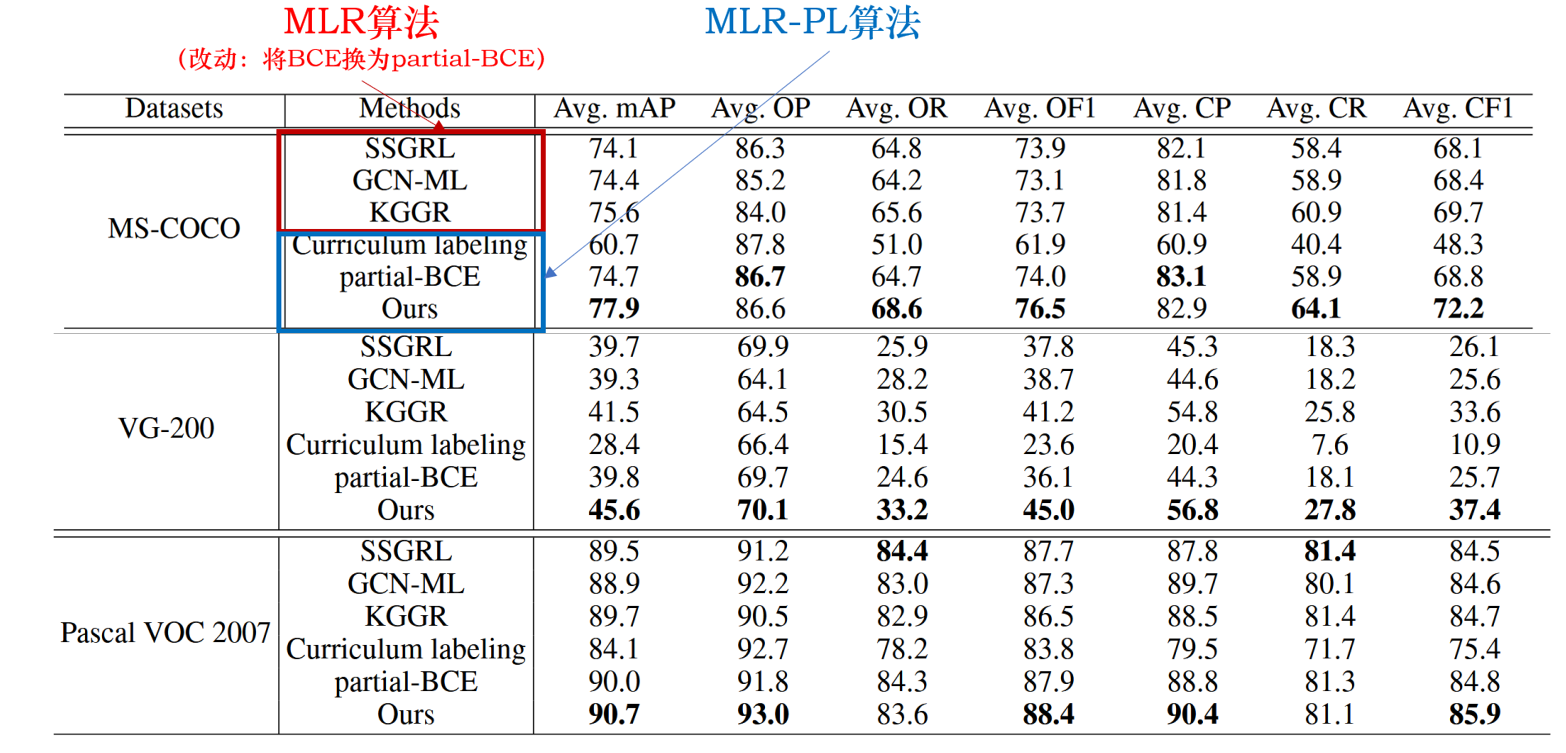
由于MLR算法是无法直接处理未知标签数据的,这里作者统一将MLR算法中的损失修改成部分二元交叉熵损失以进行对比。
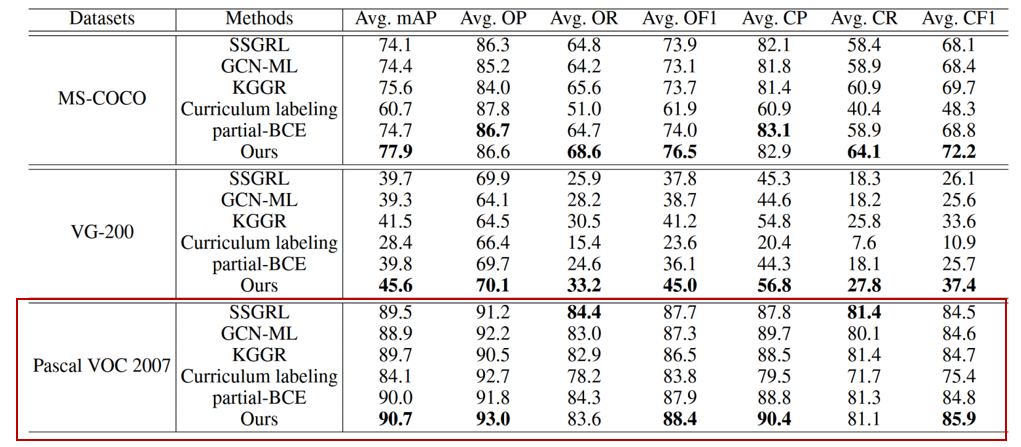
COCO数据集上表现
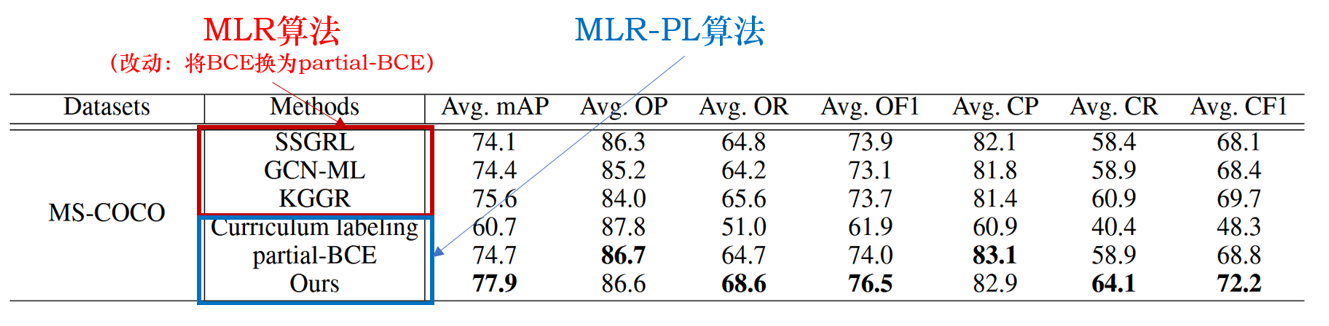
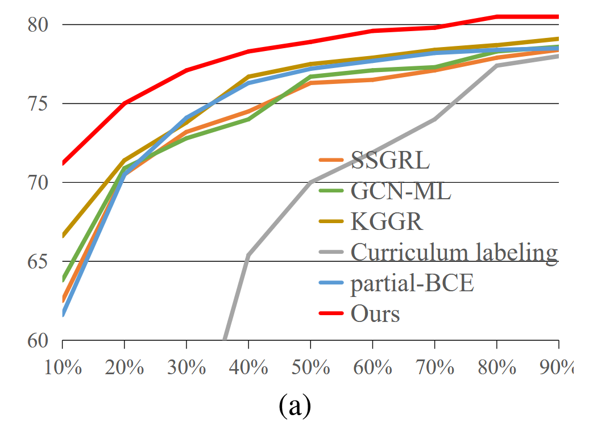
与目前最先进的算法相比,我们的 SARB 框架获得了最佳性能。(如表+图)
(列数据)如表所示,该算法的 mAP、OF1 和 CF1 平均值分别为 77.9%、76.5% 和 72.2%,比之前表现最好的 KGGR 算法分别高出 2.3%、2.8% 和 2.5%。如图所示,在所有已知标签比例设置中,SARB 框架也能获得更好的 mAP。
值得注意的是,当已知标签比例降低时,SARB 框架的性能提升更为明显。(如图)例如,当使用 90% 和 10% 的已知标签时,mAP 与之前的最佳 KGGR 算法相比分别提高了 1.4% 和 4.6%。
(摆结论)这些比较表明,SARB 框架可以适应不同的比例设置,因为它不依赖于预先训练的模型。(回应挖坑)
VG-200数据集上表现
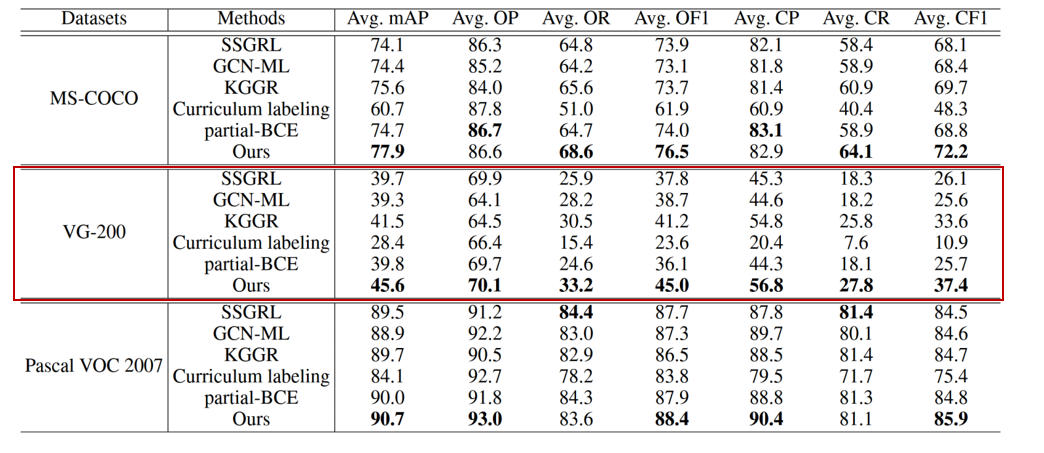
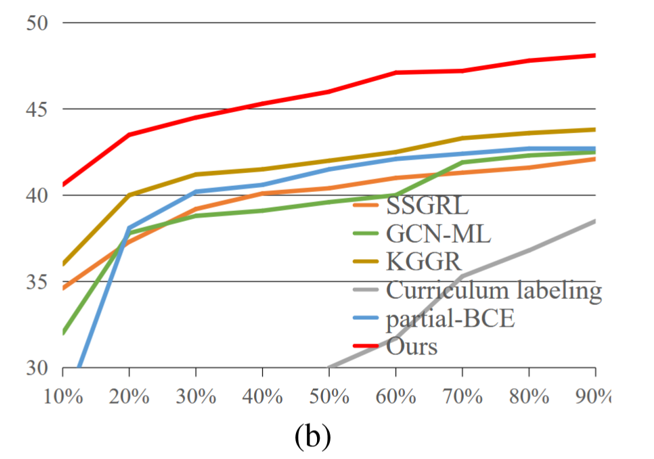
(数据背景+找补)VG200 是一个更具挑战性的基准,涵盖的类别更多。因此,目前的工作性能相当差。
(列数据)如表,之前性能最好的 KGGR 算法的 mAP、OF1 和 CF1 平均值分别为 41.5%、41.2% 和 33.6%。在这种情况下,我们的 SARB 框架表现出更明显的性能提升。其平均 mAP、OF1 和 CF1 分别为 45.6%、45.0% 和 37.4%,比 KGGR 算法分别高出 4.1%、3.8% 和 3.8%。
(列数据)如图,与现有算法相比,我们发现我们的框架在所有已知标签比例设置下的 mAP 提高了 3.3% 以上。
VOC数据集上表现
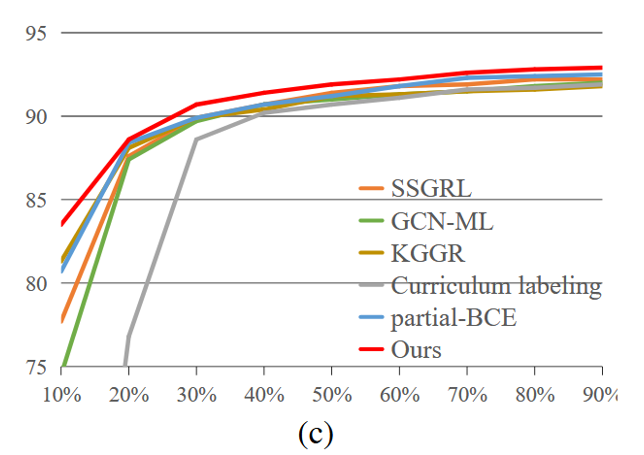
(数据背景)Pascal VOC 2007 是评估多标签图像识别最广泛使用的数据集。由于该数据集仅涵盖 20 个类别,是一个简单得多的数据集,目前的算法也能取得相当不错的性能。
(列数据)如表 1 所示,之前性能最好的 KGGR 算法的 mAP、OF1 和 CF1 平均值分别为 41.5%、41.2% 和 33.6%。在这种情况下,我们的 SARB 框架表现出更明显的性能提升。它的平均 mAP、OF1 和 CF1 分别为 45.6%、45.0% 和 37.4%,比 KGGR 算法分别高出 4.1%、3.8% 和 3.8%。
(列数据)现有算法相比,我们发现我们的框架在所有已知标签比例设置下的 mAP 提高了 3.3%。
消融实验-CSRL
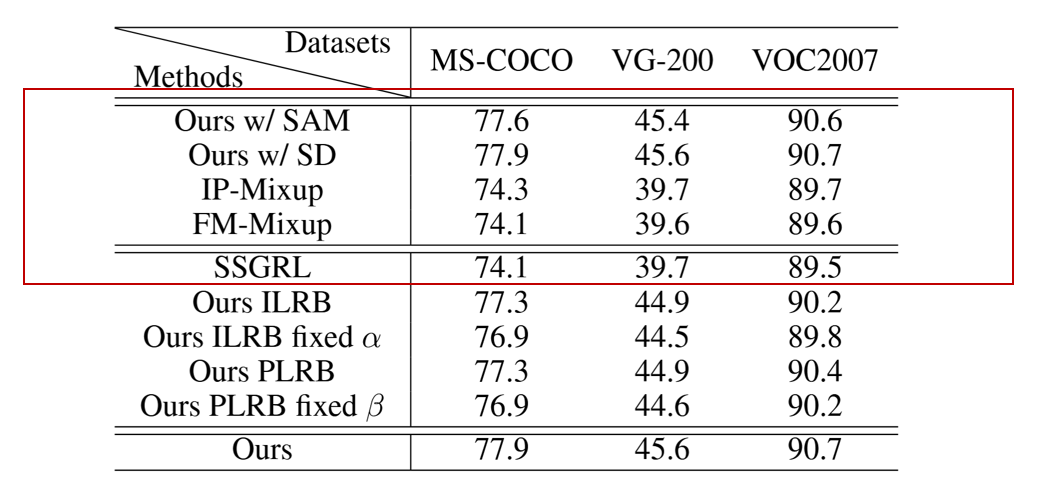
(CSRL方法)CSRL 模块用于提取类别特定的特征表征,可采用不同算法实现:语义解耦 (SD) (Chen et al.)语义注意机制 (SAM) (Ye et al. 2020)。
(基线方法)传统 Mixup 算法通过 位置级融合生成新样本,增强训练。本文实现了两个基线算法:IP-Mixup:在图像空间做融合,FM-Mixup:在特征空间做融合。(不解耦,直接融合)
(结论)SD 和 SAM 性能接近, SD 略优于 SAM,因此后续实验全部采用 SD 实现 CSRL 模块。
(结论)这两种 Mixup 与 SSGRL 基线性能相近,因为简单融合无法带来额外信息。
(结论)与 基于 CSRL 的 SARB 相比:
IP-Mixup 在三个数据集上 mAP 分别下降 3.6%、5.9%、1.0%
FM-Mixup 在三个数据集上 mAP 分别下降 3.8%、6.0%、1.1%
消融实验-ILRB
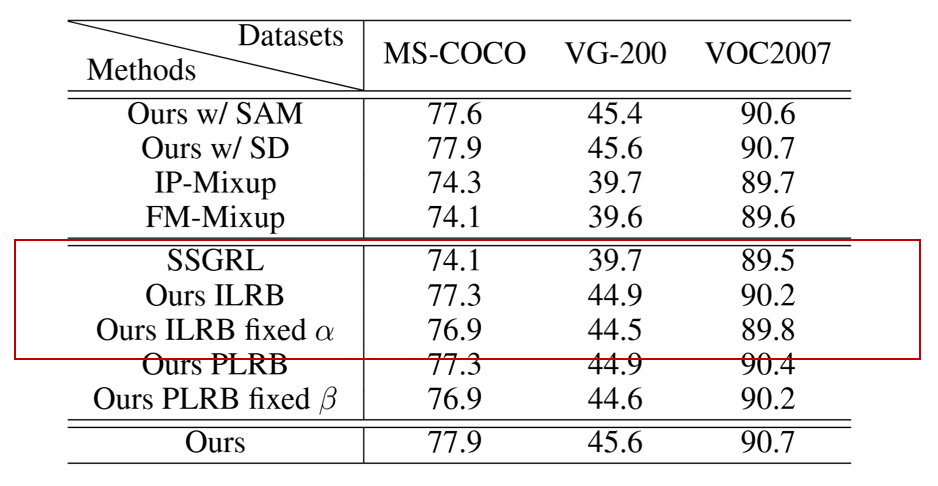
为了分析 ILRB 模块 的实际贡献,作者进行了只使用该模块的实验(称为 Ours ILRB),并与 SSGRL 基线在 MS-COCO、VG-200 和 Pascal VOC 2007 三个数据集上进行了对比。
ILRB 模块包含一个关键参数 $\alpha$,用于控制 实例级融合的比例。为了验证 $\alpha$ 的可学习性带来的贡献,作者对比了使用固定值 $\alpha=0.5$ 的情况。
(结论)实验表明,Ours ILRB在各项数据表现均优于SSGRL,mAP分别提升了3.2、5.2、0.7。
(结论)实验表明, Ours ILRB在各项数据表现均优于Ours ILRB fixed $\alpha$。说明$\alpha$ 固定会降低性能,而 自适应 $\alpha$ 更优。
消融实验-PLRB
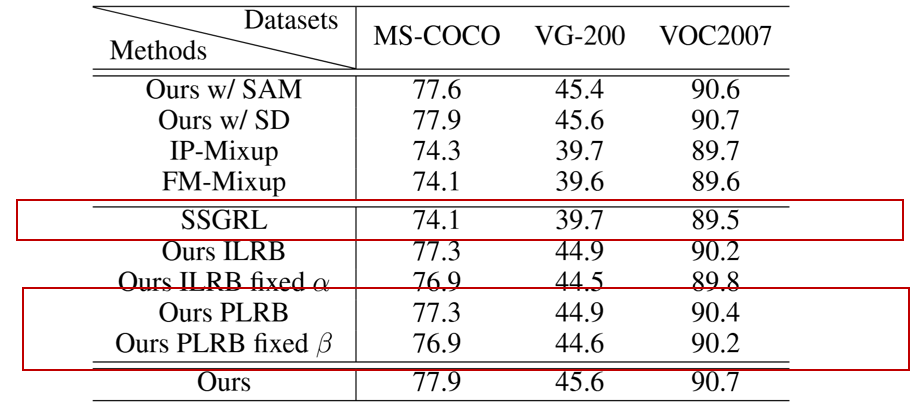
同样地,PLRB 模块也是框架中的关键部分。为了分析其有效性,作者使用了只使用PLRB的实验,并与基线SSGRL对比。同时也针对可学习参数$\beta$进行的实验。
(结论)加入 PLRB 后,相较于SSGRL,mAP分别提升了3.2、5.2、0.9。
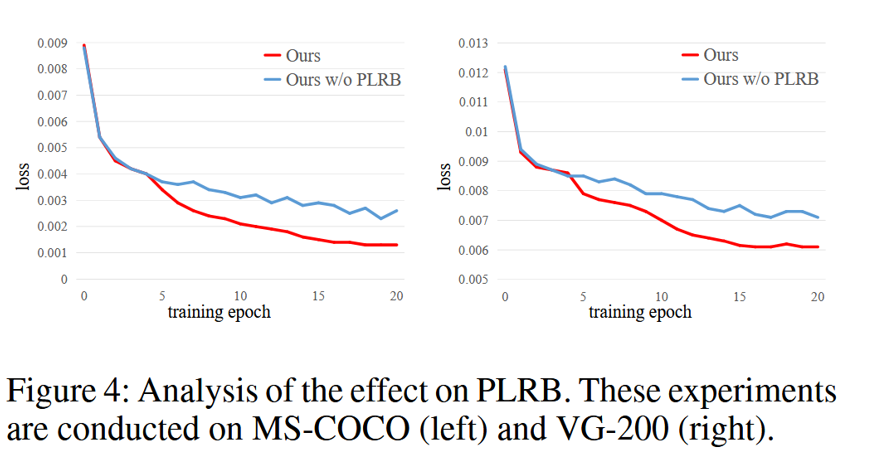
(结论)在 训练损失曲线可视化(图 4) 中可以看到:没有 PLRB → loss 波动明显(不稳定),加入 PLRB → loss 曲线更加平滑(训练稳定),根据之前的分析,PLRB 模块有助于生成稳定的融合表示,从而补充未知标签并使训练更加稳定。
(结论)自适应 $\beta$ 优于固定 $\beta$。
结论
在这项工作中,我们提出了一种新的视角:通过融合类别特定的表征来补充未知标签,从而解决 MLR-PL 任务。这种方法不依赖于充分的标注,因此在所有已知标签比例的设置下都能获得更优的性能。具体来说,我们的方法包含两个核心模块:ILRB 模块:融合已知标签的 实例级表示,以补充对应未知标签的表示;PLRB 模块:学习并融合 原型级表示,以补充对应未知标签的表示。这两个模块能够同时生成多样化且稳定的融合表示来弥补未知标签,从而促进 MLR-PL 任务的完成。在 MS-COCO、VG-200 和 Pascal VOC 数据集上的大量实验验证了该方法相较于现有算法的优越性。




