【论文阅读】:A multimodal vision–language model for generalizable annotation-free pathology localization
本论文在分享会中分享,点击查看论文PPT 👆

⭐论文信息
⭐Abstract
第一句话:开门见山:现有基于临床影像数据的病理定义深度学习模型高度依赖专家标注,且在开放式临床环境中泛化能力有限。
第二句话:所提方法:本文提出了一种具有良好泛化能力的视觉–语言模型——无标注病理定位模型(Annotation-Free pathology Localization,AFLoc)。
第三句话:核心创新:AFLoc 的核心优势在于基于多层级语义结构的对比学习机制,该机制在无需专家影像标注的情况下,将多粒度医学语义概念与丰富的图像特征进行全面对齐,从而适应病理在不同影像中的多样化表达形式。
第四句话:阐述无标注性能:我们首先在包含 22 万对影像–报告的胸部 X 光数据集 上进行了主要实验,并在 8 个外部数据集上进行了验证,覆盖 34 种胸部病理类型。实验结果表明,AFLoc 在无标注病理定位与分类任务中均显著优于当前最先进的方法。
第五句话:阐述泛化性能:此外,我们还在其他影像模态上评估了 AFLoc 的泛化能力,包括组织病理图像和眼底彩照图像。结果显示,AFLoc 具备稳健的跨模态泛化性能,在 五类病理影像的定位任务中甚至超过了人工基准水平。
⭐Introduction
段落一:【铺垫本文任务】:精确的病理定位的重要性:
(总说):医学影像中准确的诊断与精确的病理定位有助于制定个性化治疗方案,从而改善患者预后并降低误诊风险。
(具体而言):通过精确确定异常的具体位置及其范围,临床医生能够做出更加科学的决策,进而实施更具针对性的治疗策略,提高患者的整体预后效果
段落二:【引入科学问题】:监督深度学习方法严重依赖标注数据:
- (总说):在过去十年中,监督式深度学习方法显著推动了疾病定位领域的发展。然而,
这类方法的有效性在很大程度上依赖于大规模、精细标注的训练数据集,而这些数据需要领域专家投入大量时间与精力来完成。
(具体而言):具体而言,临床定位任务通常需要经验丰富的临床医生对大量影像进行精确的边界框标注,或对局部病理区域进行像素级精细勾画。
(问题):这一标注过程成本高昂,尤其在资源受限的临床环境中尤为突出,同时相关算法也往往难以在多样化的数据集之间实现良好的泛化性能。
段落三:【科学问题综述1】:微调/显著性方法 仍然依赖下游任务的标注
(总说):为降低对大规模标注数据集的依赖,已有多种方法被提出。
自监督微调:早期方法通常先通过自监督学习在大规模影像数据集上获取通用视觉表征,随后在规模较小的标注数据集上进行微调。该策略在减少数据标注需求与成本的同时,仍能在特定任务上取得较高性能。
基于显著性算法:此外,基于显著性的定位方法也被用于降低病理定位任务中的标注成本,这类方法允许在仅使用图像级标注训练的模型中,对目标类别进行粗粒度定位.
(方法不足):然而,
这些方法在具体下游任务中仍然需要相应的标注支持。在灵活且动态变化的临床环境中,这种依赖尤为棘手,尤其是在新发疾病(如 COVID-19)场景下,已部署的模型往往难以有效发挥作用。
段落四:【科学问题综述2】:无监督学习 的痛点
(总说):无监督深度学习方法因其不依赖标注数据集受到越来越多的关注,尤其是在异常检测领域。
(无监督方法介绍):这类方法通常仅使用健康样本来训练模型,从而学习正常解剖结构的分布,并在测试阶段据此识别异常的病理样本。
(无监督方法缺陷):
它们对于结构简单、样本间差异较小的数据尤为有效,能够学习规范化分布并取得优异的异常检测性能。然而,病理图像的高度异质性、不同病变之间的相似性,以及同一病灶在对比度上的大幅变化等挑战,降低了这些方法在复杂场景中的可用性,从而阻碍了其在真实医疗环境中的实际应用。
段落五:【科学问题综述3,挖坑】:VLM 的潜力与问题
(总说):一种很有前景的方向是发展医学VLM。这些方法在医学报告与医学图像之间建立有效的关联,使模型无需额外的定制化标注,就能灵活定位在预训练阶段未见过的疾病类型。
然而,仅依靠医学图像与临床报告的结合来实现精准的病灶定位仍然具有挑战性。1)临床报告中缺乏明确的病灶定位标记,报告往往只提供诸如“上部”或“左侧”等较粗略的信息来指示疾病位置。2)临床医生的描述具有主观性且差异较大,进一步增加了从医学图像中准确提取并定位疾病的难度。
(解决以上问题的综述):为应对这一问题,已有多种方法尝试融入更细粒度的信息。
— 例如,GLoRIA 提取图像区域与报告中对应词语之间的相关性,以学习图像的全局与局部表示;
— MedKLIP 则利用定义良好的医学词汇知识库,通过三元组训练范式在实体层面提供监督.挖坑,现有细粒度VLM的缺陷:然而,这些细粒度方法通常只关注医学概念的某一单独层级,可能忽略同一概念在不同语境下语义的可变性。因此,它们在适应临床实践中多样化的疾病描述表达时可能存在困难,并且常常需要定制化的文本提示来提升定位性能。
段落六:【填坑与实验】:本文方法与性能
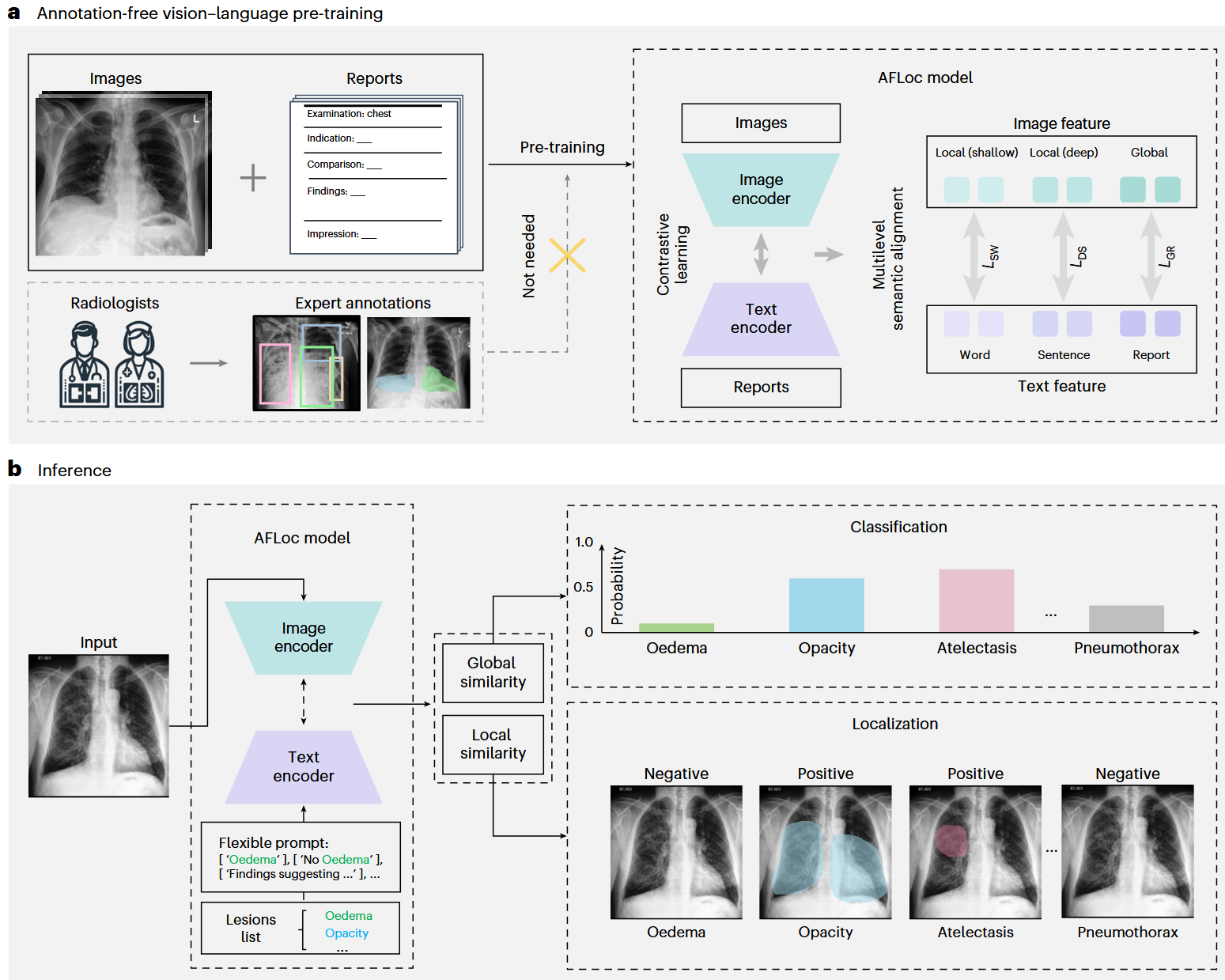
(总说):我们提出了 AFLoc,这是一种基于对比学习的视觉—语言模型,旨在缓解对昂贵病灶定位标注的需求。AFLoc 能够仅凭医学图像自主完成病灶定位与临床诊断。
(技术创新):不同于传统的全局语义对齐策略,AFLoc 引入了带有多层级语义对齐组件的对比学习框架,从而促进报告中的医学概念与图像特征之间的全面对齐。
具体而言,图像编码器生成三种层级的特征:
浅层局部特征、深层局部特征和全局特征;这些特征分别与文本编码器提取的词级、句级以及报告级特征进行对齐。(性能展示):我们在三类医学图像数据集上对 AFLoc 进行了广泛验证,包括胸部 X 光(8 个外部数据集)、组织病理图像(3 个外部数据集)以及视网膜眼底图像。结果表明,AFLoc 在不同模态的定位与临床诊断任务上均优于当前最先进的方法。
(展望):我们希望本研究能够帮助应对临床环境中标注稀缺与模态多样性带来的挑战,并为未来临床开放环境方法的设计提供启示。
⭐methodology