
【论文阅读】:Large Loss Matters in Weakly Supervised Multi-Label Classification
本论文在论文分享会中分享,点击查看论文PPT 👆

⭐论文信息
1.1 拟解决的科学问题
✨ 本论文旨在解决多标签数据集中标签部分遗漏的问题。
✨ 本文属于 弱监督学习 领域。具体属于 弱标签学习 领域或 弱监督多标签学习(WSML) 领域。
⭐论文背景
2.1 基本背景
✨ 弱监督多标签学习(WSML)
In a WSML setting, labels are given as a form of partial label, which means only a small amount of categories is annotated per image. This setting reflects the recently released large-scale multi-label datasets [12,19] which provide only partial label.
✨ 传统解决方案流派:
第一种是:忽略部分缺失标签,直接拿已有标签进行训练。
第二种是:直接把部分缺失标签判定为负样本,进行训练。
There are two naive approaches to train the model with partial labels. One is to train the model with observed labels only, ignoring the unobserved labels. The other is to assume all unobserved labels are negative and incorporate them into training because majorities of labels are negative in a multilabel setting [32].
✨ 记忆效应:模型在训练时会首先记住干净标签,而之后再学习噪声标签。(如图所示,干净标签的样本损失一直下降,而噪声标签的样本损失则先上升后下降)
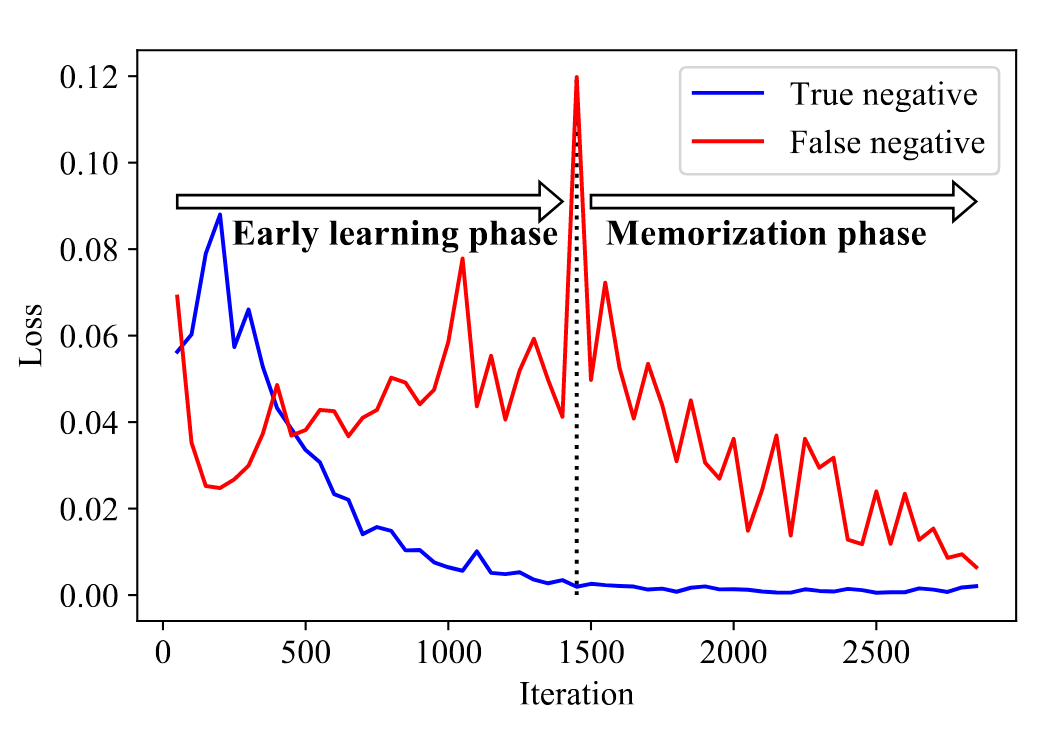
2.2 挖坑
✨ 现有数据集中一个实例实际上可能有多个标签,然而多标签的数据标注费时费力且难度大,影响了模型的性能。
However, the multi-label classification task has some fundamental difficulties in making a dataset because it requires annotators to label all categories’ existence/absence for every image. As the number of categories and images in the dataset increase, annotation cost becomes tremendous [19].
✨ 第一种解决流派的前沿技术具有算力要求高、优化更复杂的缺陷;而第二种解决流派则将带噪的标签引入模型,影响模型的学习。
As the second one has a limitation that this assumption produces some noise in a label which hampers the model learning, previous works [7,9,16,21] mostly follow the first approach and try to explore the cue of unobserved labels using various techniques such as bootstrapping or regularization. However, these approaches include heavy computation or complex optimization pipeline.
2.3 一段话介绍技术
基于这一发现,我们借鉴了噪声多类别领域文献中的思想[13, 17, 23],即通过选择性地训练具有小损失的样本,并将这一思想应用于多标签情境。具体来说,通过在WSML设置中将未知标签视为负标签,标签噪声以假阴性的形式出现。然后,我们开发了三种不同的方案,通过在训练过程中拒绝或修正大损失样本,防止假阴性标签被记忆到多标签分类模型中。
Based on this finding, we borrow the idea from noisy multi-class literature [13, 17, 23] which selectively trains the model with samples having small loss and adapt this idea into a multi-label scenario. Specifically, by assigning the unknown labels as negative in a WSML setting, label noise appears in the form of false negative. Then we develop the three different schemes to prevent false negative labels from being memorized into the multi-label classification model by rejecting or correcting large loss samples during training.
2.4 相关工作
主要可以把相关工作分为三类:多标签学习、弱监督多标签分类、带噪多分类。他们的工作可以列举如下表格:
| 研究领域/研究方法 | 流派1 | 流派2 | 流派3 | 流派4 |
|---|---|---|---|---|
| 多标签学习 | 研究标签相关性 | 研究数据不平衡 | ||
| 弱监督多标签分类 WSML | 忽略缺失标签方法训练 | 借助标签相关性和图像相关性预测缺失标签 | 训练时,只选择一个正标签学习,使用正则化优化分类器和缺失标签预测 | 直接把缺失标签判定为负样本 |
| 带噪多分类 | 样本筛选策略 | 标签修正策略 | 样本筛选 + 标签修正 |
⭐论文方法
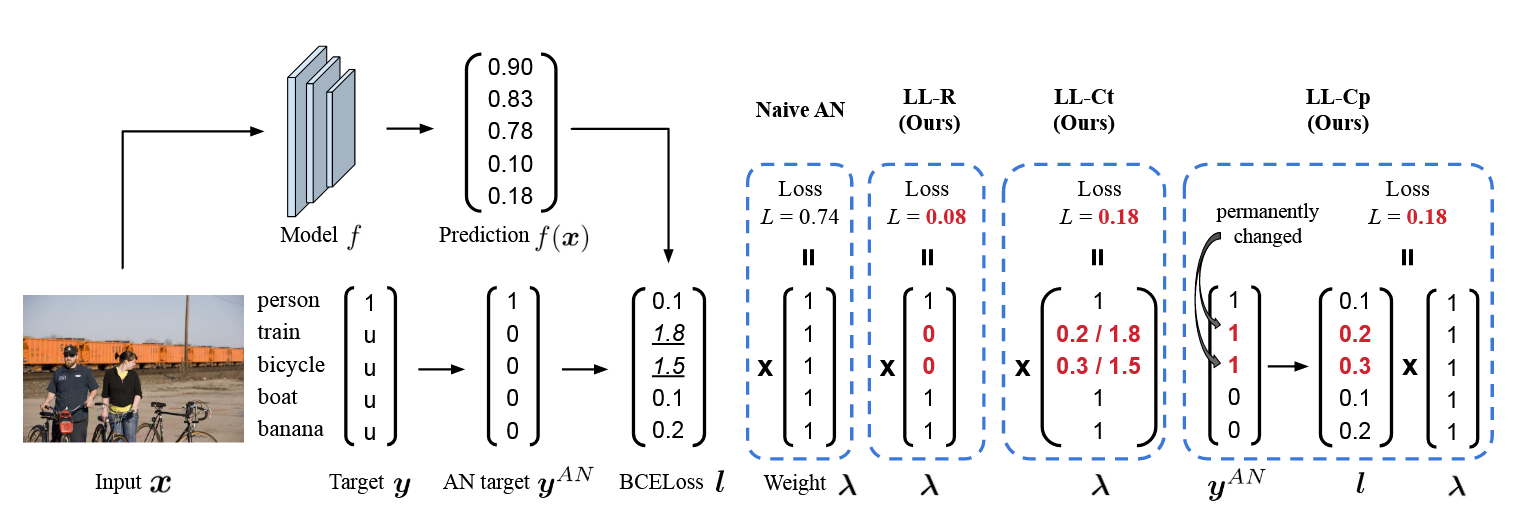
对于一个样本$\boldsymbol{x}$,它的标注的标签为 Targrt $\boldsymbol{y}$,我们首先假定$\boldsymbol{y}$中所有缺失的标签都是负标签进而获得$\boldsymbol{y}^{AN}$。然后我们通过一个预测器$\boldsymbol{f}$来预测$\boldsymbol{y}^{AN}$,得到$g(\boldsymbol{x})$,之后计算它们的交叉熵$\boldsymbol{l}=\text{BCE}{(f(\boldsymbol{x}),\boldsymbol{y}^{AN})}$。接着我们通过三种修正方法来修正$\boldsymbol{l}$,分别是大损失标签拒绝(LL-R)、大损失标签临时修正(LL-Ct)、大损失标签修正(LL-Cp)。假设有$N$个训练样本,每个样本有$K$个标签。
3.1 大损失标签拒绝(LL-R)
该方法的核心思想是拒绝大损失标签(注意是拒绝标签,不是拒绝样本),即当$\boldsymbol{l}$大于阈值$R(t)$时,我们拒绝该标签的梯度更新。这样可以防止模型记忆噪声标签,其中$R(t)$的设定有点令人晕晕的;而防止模型记忆噪声标签的设计是通过修正$\boldsymbol{l}$来实现的,具体是设计了损失权值$\lambda$,使得$\boldsymbol{l}$拒绝较大的损失标签。
阈值设计
LL-R中阈值$R(t)$是一个随着训练轮次$t$逐渐增大的函数,其设计如下:
其中$\boldsymbol{l}_{\text{max}}$是当前训练轮次中的最大损失,例如当$[(t-1)\cdot \Delta_{rel}] \%=0.8$时,$R(t)$将当前轮次损失前$80\%$大的损失(不是最大值乘以0.8,假定这轮每一个样本有100个样本,每一个样本有2个标签缺失,则总共有200个标签缺失,则这个阈值即按算是大到小排列第160个缺失标签的BCE损失)作为阈值。这种设计导致随着训练轮次的增加,阈值$R(t)$的百分比逐渐增大,从而拒绝更多的大损失标签。其中$\Delta_{rel}$是一个超参数,用于控制阈值的增长速度。应该注意到,当$t=1$时,$R(t)=0$,即第一轮 (预热阶段)不会拒绝任何标签。
我觉得这种设计令人费解,为什么阈值按照百分比进行设定,这种设计导致每一轮必须淘汰掉一定比例的标签,这样的设计是否合理?为什么不直接设定一个损失阈值呢,甚至直接拿本轮损失的最大值乘以一个系数作为阈值?
损失权值设计
为了拒绝大损失标签,LL-R设计了一个损失权值$\lambda$,使得$\boldsymbol{l}$拒绝较大的损失标签。具体来说,我们通过以下公式来计算$\lambda$:
这里$\boldsymbol{l}_i$是样本$\boldsymbol{x}$的第$i$个标签的损失,$R(t)$是阈值,$\lambda_i$是损失权值。这样,当$\boldsymbol{l}_i$大于阈值$R(t)$且该标签是缺失标签时,我们将$\lambda_i$设为0,即拒绝该标签的梯度更新。这样,我们可以防止模型记忆噪声标签;最终计算的损失为:
这样,我们可以通过拒绝大损失标签来防止模型记忆噪声标签。
3.2 大损失标签临时修正(LL-Ct)
该方法的核心思想是在训练过程中,临时修正大损失标签,即当$\boldsymbol{L}$大于阈值$R(t)$时,我们临时修正该标签并重新参与损失计算。它也是通过设计损失权值$\lambda$来实现的,其设计如下:
最终计算的损失和LL-R一样,只是$\lambda_i$的设计不同。
值得注意的是,当$\boldsymbol{l}_i$大于阈值$R(t)$且该标签是缺失标签时,我们将$\lambda_i$设为$\frac{\log f(\boldsymbol{x})_i}{\log (1-f(\boldsymbol{x})_i)}$,即临时修正该标签(直接从0暂时改为1)并重新参与损失计算,具体推导如下:
具体计算负标签的$\boldsymbol{l}_i$可以获得如下:
具体计算$\text{BCE}_{\text{neg}}$,并且代入$\lambda_i=\frac{\log f(\boldsymbol{x})_i}{\log (1-f(\boldsymbol{x})_i)}$,可以得到:
即得到:
这样,我们在计算损失时,就可以视作标签从负样本变成了正样本,损失权重$\lambda_i$从$\frac{\log f(\boldsymbol{x})_i}{\log (1-f(\boldsymbol{x})_i)}$变成了1,证明做到了临时修正。
3.3 大损失标签修正(LL-Cp)
该方法的核心思想是在训练过程中,修正大损失标签,即当$\boldsymbol{L}$大于阈值$R(t)$时,我们直接将该标签修正为正标签并进行下一轮训练。其设计如下:
首先这里阈值的设计有所不同,其将$R(t)$设定为一个固定值,并不随着训练轮次的增加而增加。
其次对于获得的标签$\boldsymbol{y}^{AN}$,它将随时可能被修正为正标签,具体的修正方法如下:
修正后,直接计算交叉熵损失即可,即:
这样,我们可以通过修正大损失标签来防止模型记忆噪声标签,这是一个永久性的修正,而不是临时修正。
⭐实验设定
4.1 SOTA对比实验
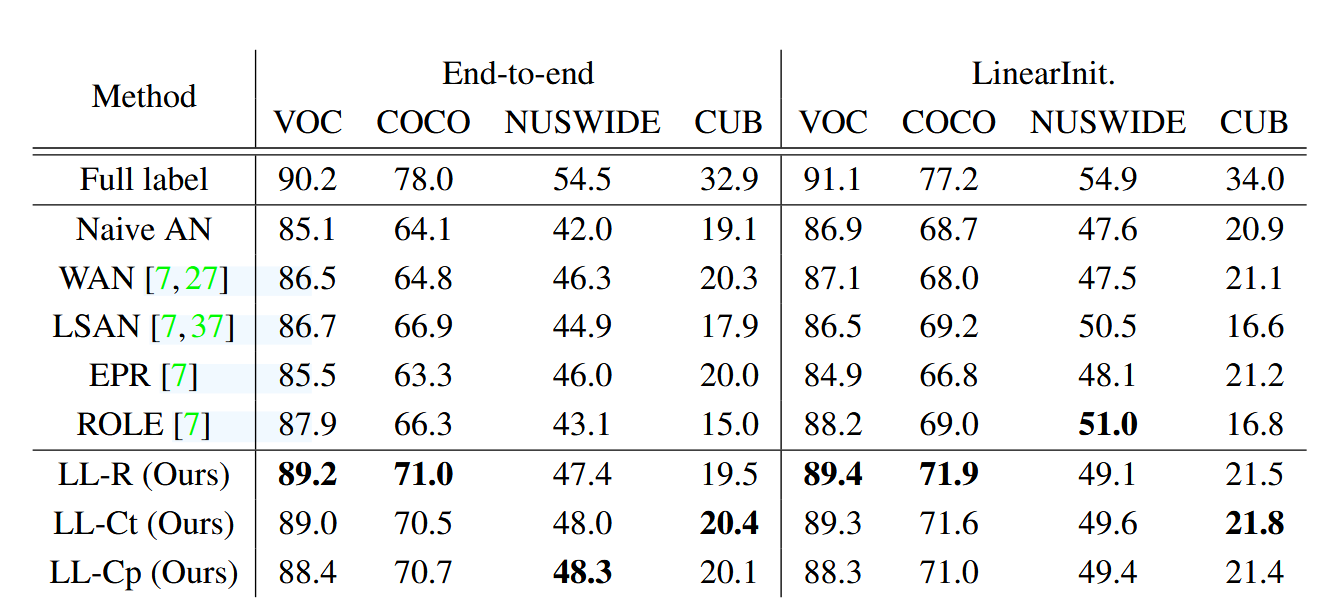
✨人工创造不完整多标签数据集
数据集说明:将现有的多标签数据集中的部分标签进行删除,从而构建不完整多标签数据集。具体来说,我们从现有的多标签数据集中只随机保留一个正标签,其余标签全部删除。所使用的数据集包括VOC 2012、MS COCO 2014、NUSWIDE和CUB。其中CUB是一个鸟类分类的数据集,注意这里我们不用于预测鸟类分类任务,而是用于预测鸟类的多标签特征例如颜色、形状等。
数据处理:本文具体对数据进行了如下处理:
- 使用相同的种子数来随机删除标签,以确保每个数据集的不完整多标签数据集是相同的。
- 测试模型选用在ImageNet上预训练的ResNet-50模型。
- 模型训练的Batch Size设置为 16。
- 训练时采取随机水平翻转进行数据增强。
- 所有输入图像的大小都调整为 448x448。
- 设定俩种训练策略,一种是LinearInit,另一种是End-to-end,其中LinearInit是在第一轮训练时,只训练模型最后一层,其余层的参数保持不变;End-to-end是直接训练整个模型。
对比方法:本文将提出的三种方法的俩种训练模式分别与以下方法进行对比:Full label:直接使用完整标签训练模型;Naive AN、Weak AN(WAN)、Label Smoothing with ANLSAN、和ROLE。以上均是第二种解决流派的前沿方法;由于实验设定与第一种解决流派的前沿方法不同,因此不进行对比。
实验结果:结果如下图。
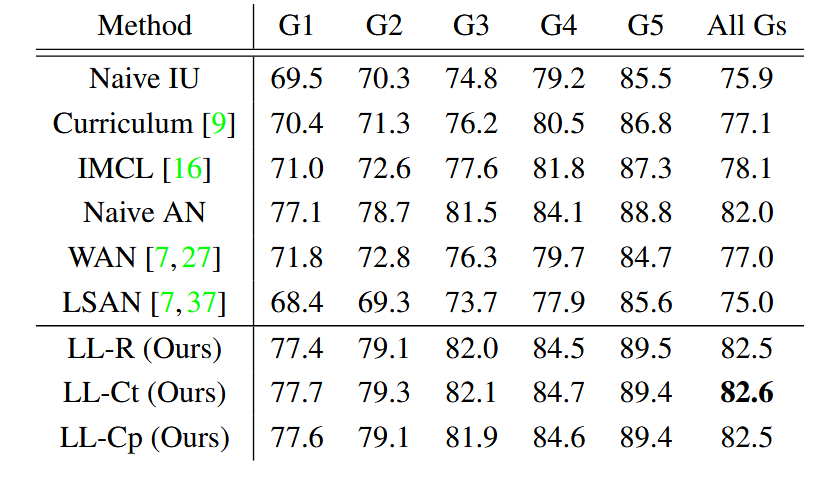
✨真实部分标注的数据集
数据集说明:这里使用了OpenImages V3数据集,该数据集包含了3.4M的训练图像、42K的验证图像和125K的测试图像,并且有5000个类别,且只有不到$1\%$的标签是被标注的。
数据处理:本文具体对数据进行了如下处理:
- 测试模型选用ImageNet-pretrained ResNet-101模型。
- 模型训练的Batch Size设置为 288,使用4个GPU。
- 所有输入图像的大小都调整为 224x224。
- 训练时采取随机水平翻转进行数据增强。
- 由于不同类别对应的图像数据的量是不同的,作者将数据集分为了5组,每一组有1000个类别,其中Group 1是数据量最小,Group 5是数据量最大。
对比方法:本文将提出的三种方法的俩种训练模式分别与以下方法进行对比:第一种流派技术Naive IU、Curriculum labeling、IMCL。第二种流派技术Naive AN、WAN、LSAN。
实验结果:结果如下图。
4.2 消融实验
消融实验主要分别对所提的损失修正方法和超参数$\Delta_{rel}$进行了实验,具体如下:
✨损失修正消融实验
这里似乎也不完全可以称为消融实验,本实验主要是证明三种损失修正的模块的有效性。这里作者定义了其评价指标:修正准确率,其定义为模型成功修正或拒绝的标签数量与模型所有修正或拒绝的标签数量的比值。显然,修正准确率代表模型修正 假阴性标签 的能力。其实验结果如下:
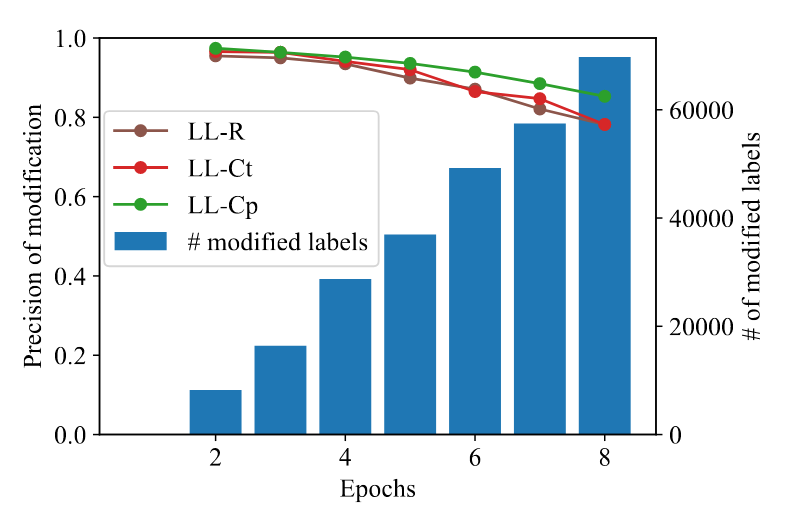
图中蓝色柱状线对应模型某一轮修正的总标签数,三种折线分别表示三种修正方法的修正准确率。从图中可以看出,三种修正方法都能保证修正准确率高水平,说明三种方法确实对错误的标签进行的正确的处理。然而随着训练轮次的增加,修正准确率逐渐下降,这是因为随着训练轮次的增加,模型记忆噪声标签的能力增强,导致修正准确率下降。此外,三种方法中修正准确率最高的是LL-Cp,然后实际上分类性能最好的并不是LL-Cp,这是因为LL-Cp修正的标签是永久性的,一旦LL-Cp错误地修改了一个标签,它反而会降低模型的性能(这种方法过于激进)。
可能读者可能还是疑惑为什么随着训练轮次的增加,修正准确率逐渐下降,难道我们的模型不就是为了解决模型后半期记忆噪声标签的问题吗?这里是因为只要没有百分百的错误标签被修正或拒绝,训练后期它一定会被记住,一旦这些错误标签影响了模型的表征,模型性能就会下降,性能一下降原本可能真阴性的样本可能也被误判为假阴性,导致修正准确率下降。
✨超参数$\Delta_{rel}$消融实验
这里作者主要是对超参数$\Delta_{rel}$进行了实验,分别选取$\Delta_{rel}=0.1$到$10$进行的实验,统计LL-Ct不同超参数下的模型分类准确率。实验结果如下:
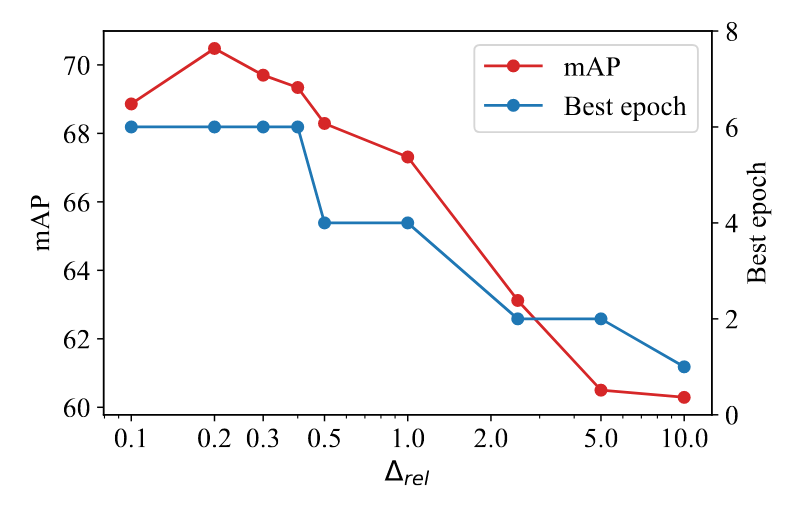
可以看出此实验最佳的拒绝增长系数$\Delta_{rel}$是0.2。其中过小的$\Delta_{rel}$会导致模型在训练时没有拒绝足够多的假阴性标签,而过大的$\Delta_{rel}$会导致模型在训练时错误地把一些真阴性标签拒绝,从而影响模型的性能。
4.3 可视化实验
这里主要就是举了几个具体的例子,效果如下:

可以看出,所提方法可以有效地把把图片中缺失的视觉特征预测出来,第四张图是一个错误的例子,模型把卡车错误地预测为汽车,还莫名其妙预测出来个人。
4.4 其他实验
这里作者还进行了一些其他实验:可解释性实验、小数据训练实验,这里只介绍小数据训练实验,具体如下:
作者主要对COCO数据集进行了实验,根据原训练数据的$10\%$、$20\%$、$30\%$、$40\%$、$50\%$、$60\%$、$70\%$、$80\%$、$90\%$、$100\%$的标签进行训练,实验结果如下:
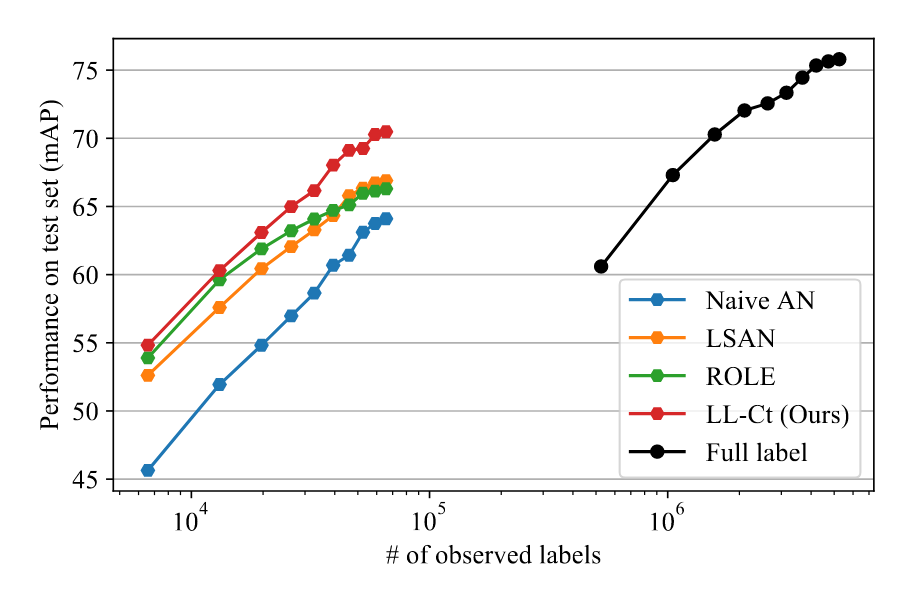
可以看出,所提方法在小数据训练上的效果也是非常好的,超越其他现有方法,且准确率相当于全标签训练的效果。
⭐笔者总结
本文主要为笔者提供了一个新的研究领域:弱监督多标签学习(WSML),这个问题在医学CT影像处理十分常见,它的方案也为我提供了一个可行的思路。
具体地,此文章沿用了“将未知标签视为负标签”的思路,将缺标签的多标签分类转化为了噪声多标签分类问题,并发现了噪声多标签分类中存在类似于噪声多分类问题的记忆效应。并提出了通过修正或拒绝大损失标签的方法来防止模型记忆噪声标签,这种方法简单且有效。






